
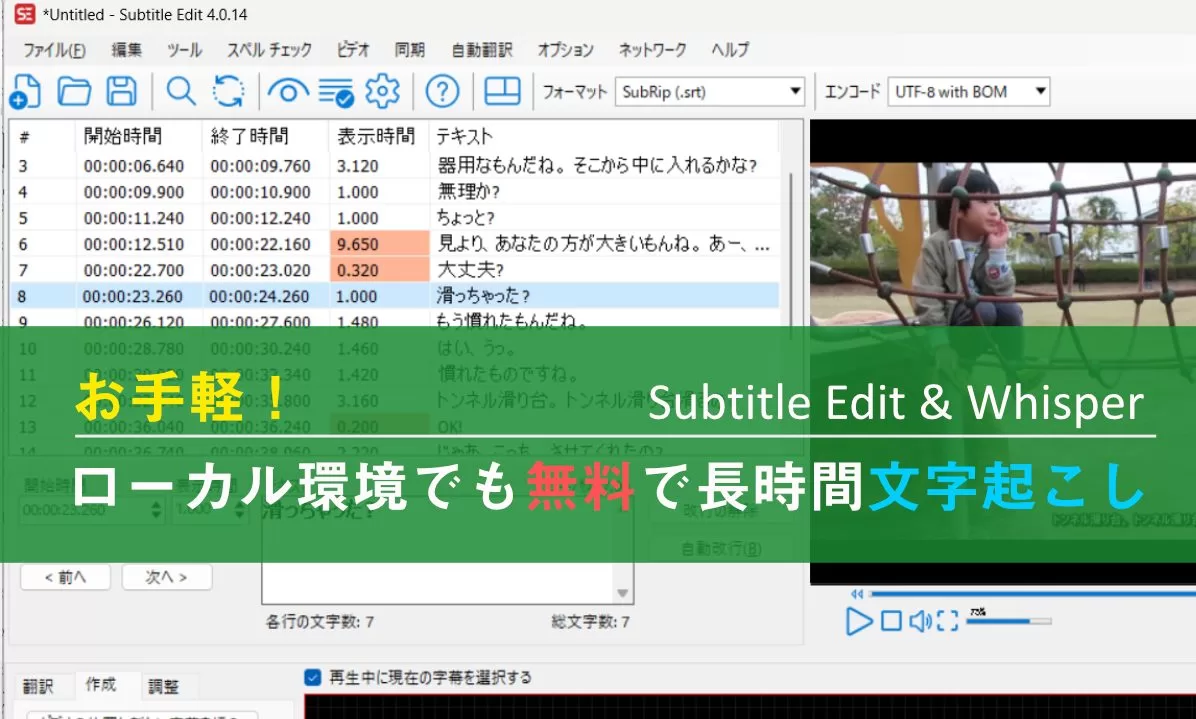
前回の記事では、Whisper と Python を使い、Chunk処理とGPUで力技の長時間音声文字起こしに挑戦した。
RTX3060 を積んだ環境で4時間の議会録音を約10分で処理できたのは面白い成果だったが、正直セットアップは人にすすめにくい。
しかし──
実は同じことをもっと簡単に、しかも無料で、ソフト一本だけでできる方法が存在する。
それが今回紹介する Subtitle Edit(以下 SE)+ Whisperモデル だ。

① Subtitle Edit が再注目される理由
Subtitle Edit自体は古くからある字幕ツールだが、近年Whisperモデルが統合されたことで用途が一気に広がった。
ハードルが下がった理由はこれだけで説明できる:
Whisperを自分でインストールしなくていい。
モデル選んでボタン押すだけ。さらに、
- 長時間音声対応
- CPUでも十分動く
- CUDAにも対応
- Output形式が豊富
- 自動句読点・整形補助付き
- オフライン動作
- 文字起こし->翻訳までを一括サポート
これにより、
「専門知識がある人の遊び」
↓
「一般ユーザーでも扱える実用ツール」
へ変化した。
② Whisper系文字起こしの実用比較
同じWhisperでも「環境」と「目的」で適正が違う。
まとめるとこうなる:
| 方法 | 予算 | 難易度 | 精度 | 長時間対応 | 向いてる用途 |
|---|---|---|---|---|---|
| Whisper + Python(ローカル) | 無料 | 中級者向け | ◎ | ◎ | 研究・自動化 |
| Subtitle Edit + Whisper | 無料 | 最も簡単 | ○〜◎ | ◎ | 議事録・講義・会議録 |
| Notta・Otter.ai | 有料(月額) | 初心者OK | ◎ | ◎ | 共同編集・クラウド共有 |
| Teams/Google | 企業課金依存 | 簡単 | ○ | △ | 企業内限定 |
「無料で長時間処理したい」なら SE が現時点の最適解。
③ 実際の操作ステップ
今回も、映像素材には春日部市議会の公式アーカイブ映像を使用。
Step 1.音声・動画データを読み込む
対応形式は動画(mp4 / mov / mkv)でも音声(wav / mp3)でもOK。
長時間ファイルでも止まらない。
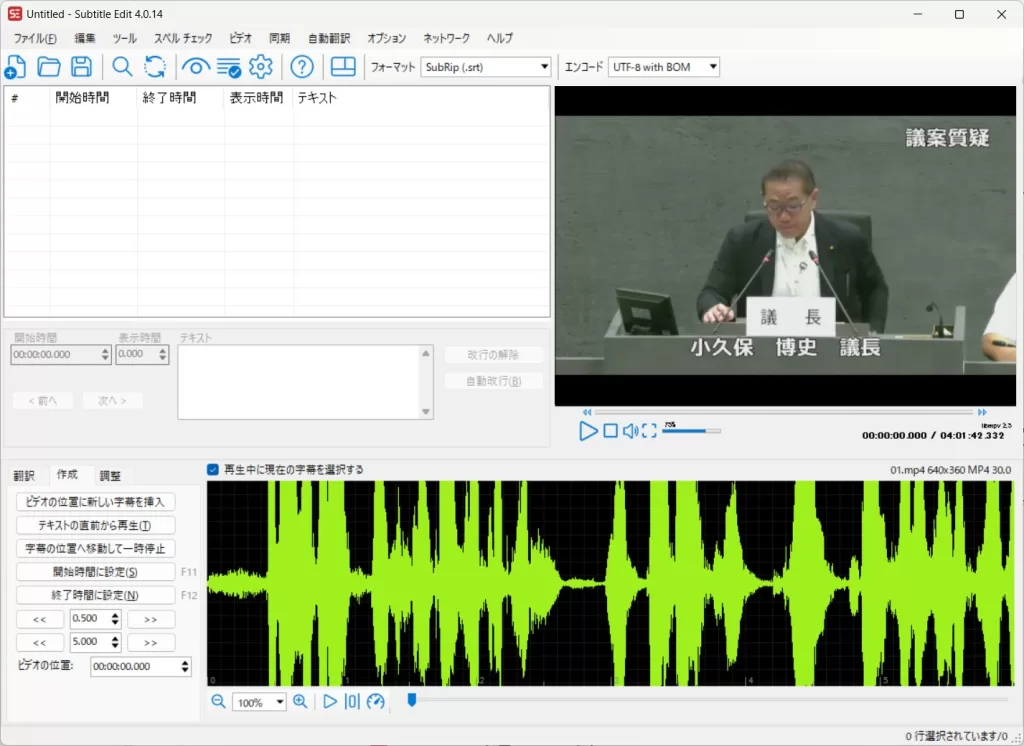
👉 動画ファイルをドロップ(または”開く”)
Step 2.Whisperモデルを選択
モデルは tiny → base → small → medium → large とあるが、体感:
- 会議録・議会・説明会 → small 以上推奨
- 雑談・ひとり語り → base でも可
対象言語は”Japanese”。
![Subtitle Editで文字起こし。
Whisperモデル選択画面 [ビデオ → Audio to Text(Whisper) から開ける]](https://b.aries67.com/wp-content/uploads/2025/11/image-10.webp)
👉 Whisperモデル選択画面 [ビデオ → Audio to Text(Whisper) から開ける]
Step 3.変換を実行 → 自動整形
“Genarate”ボタンを押したら、オーディオの抽出がはじまり、数分待てばテキスト化が完了。
この時点ですでに「句読点あり」「段落付き」「余計なノイズ除外」の状態になる。


④ 精度検証(リアル誤変換例)
今回も対象は議会音声(約4時間)。前回のPython+Whisper手動処理と比較すると、Subtitle Edit版は明らかに誤変換数が減りました。
代表例:
| 誤変換 | 正しい語句 |
|---|---|
| 精神病床への入院費は対障害 | → 対象外 |
固有名詞や制度名称など、音声が似ている語は依然として取りこぼしがありますが、文脈がある一般語句や助詞の処理精度は向上していました。
なぜ精度が上がったのか?(推測)
Whisperモデル自体は同じでも、Subtitle Edit側が以下の改良をしている可能性があります:
- 前処理(ノイズ除去)の最適化
- 文脈推定アルゴリズムの改善
- モデルの実装最適化(句読点補正・未知語推定処理)
- 内部辞書の更新 & Whisper出力補正のロジック修正
特に今回、前回ミスが多かった接続詞・語尾・医療系表現の認識が改善しており、
「機械がただ聞いた字を出す」段階から、
「音声を“文章として”理解しようとする挙動」に近づいている印象です。
結論:精度は上がった。でも、人力チェックは必須。
一方、依然、誤変換の課題は残存。
| 誤変換 | 正しい語句 |
|---|---|
| 全会一致で、この10度、心身障害者医療費助成制度 | → この重度 |
Subtitle Editは優秀です。
しかし、行政文書・制度名称・固有名詞が絡む議事録では、
AIの出力をそのまま公開するのは危険。
最適な姿勢は変わりません:
AIに9割やらせ、最後の1割は人間が確認する。
これが現時点での、最も現実的で、ストレスが少ないやり方です。
便利すぎた編集機能
- ✔ タイムコード削除
- ✔ 行ごとの短文 → 自動長文結合
- ✔ 誤変換ワード一括置換
- ✔ Word / TXT / SRT / PDF 出力
- 文字起こしした字幕入り動画もすぐ生成


どんな用途に向くか
- 学校・講義の書き起こし
- PTA / 町内会 / マンション管理組合
- 自治体議事録
- YouTube字幕
- 取材・対談・インタビュー
- 超ロングな文字起こし
- 人間による精緻な補正作業
- 門外不出の情報を扱う
特に情報漏洩が気になるケースならSEがベスト。
課題・注意点(期待値コントロール)
- 話者識別は弱い
- 専門語・地名・固有名詞は要修正
- 「要約機能」はない(今は文字化に特化)
それでも“手作業0→確認作業だけ”に変わるのは大きい。
まとめ
Whisperを動かすための環境づくりが武器だった時代は終わった。
今は、Subtitle Editの「ボタン一つ」で誰でも実用レベルの議事録が作れる。
編集者・議員・広報・町内会・講義・研究──
用途は広く、無料でここまでできるのは普通に驚異。
最近は、クラウドサービスでも相当無料で使えるサービスがある。
例えば、soundwise.ai では、4時間の音声を一括で扱うことは出来なかった。

4時間という長尺音声を気軽に扱うのに、Subtilte Edit はお気楽で有力な選択肢だ。
あなたも、いますぐ無料で試せるのだから..。

