

Search Consoleで「クロール済み – インデックス未登録」が増える理由
これまでSEOの世界では、情報の価値はおおむね三つの軸で語られてきた。
情報の量。
情報の鮮度。
そしてユニークさ。
多くのWebメディアやブログは、この三つを意識してコンテンツを作ってきた。
記事を増やし、更新を続け、他サイトとは違う視点を提供する。
この原則は、長い間かなり有効に機能していた。
しかし現在、この前提そのものが変わり始めている。
生成AIの登場によって、文章を作ること自体はほとんどコストのかからない作業になった。
記事を書くことは、もはや特別な労力ではない。
その結果、Web上のコンテンツはこれまでにない速度で増え始めている。
そして今、検索エンジンの側にも変化が起きている。
Search Consoleを観察していると、
インデックスされるページ数が減っていく
という奇妙な現象が見えてくる。
ページは存在している。
しかし、検索インデックスには登録されない。
これは単なるアルゴリズムの揺れなのだろうか。
それとも、AIコンテンツ爆発に対する検索エンジンの構造的な変化なのだろうか。
この記事では、Search Consoleの観測データを手がかりに、
AI時代のGoogle検索で起きている変化を整理してみたい。
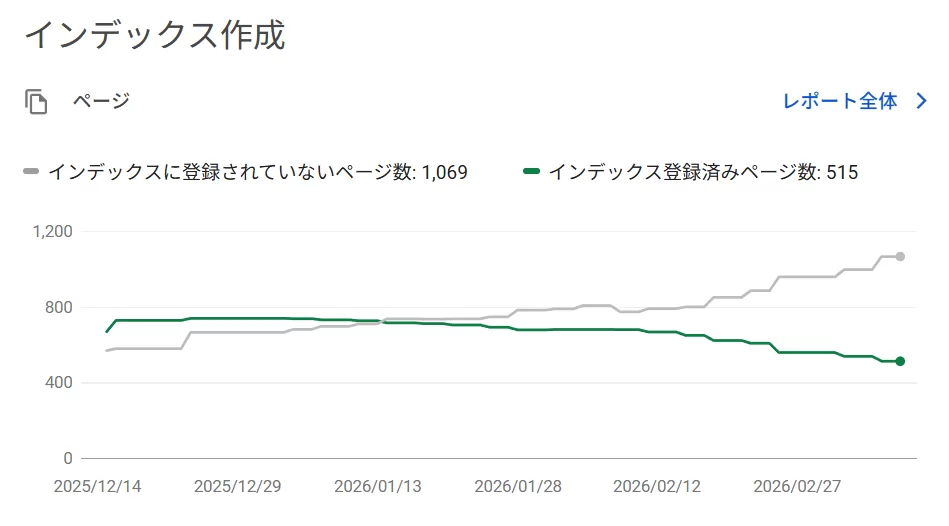
この変化は一度のアルゴリズム更新というより、数週間にわたって徐々に進んでいる。Search Consoleのグラフを見る限り、Googleはページを急激に削除しているのではなく、時間をかけてインデックスの整理を進めているように見える。
第1章 AI生成コンテンツ爆発という新しい状況
Webという空間は、長い間「人間の労力」によって拡張されてきた。
記事を書く。
調査する。
編集する。
公開する。
一つのページが公開されるまでには、必ず人間の時間が必要だった。
そのため、Webページの増加速度には自然な上限が存在していた。
しかし生成AIの登場によって、この前提が大きく変わり始めている。
現在では、大規模言語モデル(LLM)を使えば、数千文字の記事をわずが数秒で生成することができる。
さらに投稿ツールや自動化システムを組み合わせれば、1日に数十、あるいは数百ページを公開することも技術的には難しくない。
つまり、Webのコンテンツ生成コストは急激に下がった。
かつて
記事生成
= 人間の時間
だったものが、
記事生成
= 計算資源
へと変化したのである。
この変化は、単なる効率化ではない。
Webのページ数そのものを、これまでとは異なる速度で増加させる要因になっている。
実際、SEOコミュニティではここ数年で
・AIによる記事量産サイト
・自動生成されたブログネットワーク
・プログラムによる大量ページ生成
といった事例が急速に増えている。
これはかつて存在した「コンテンツファーム」の、AI時代版とも言える現象だ。
実際、AIによるコンテンツ増加はデータでも確認されている。
SEOツールAhrefsが約90万ページを分析した調査では、2025年に公開された新規Webページの 74%にAI生成コンテンツが含まれていた と報告されている。
新規ウェブページの 74% に AI 生成コンテンツ。90 万件を大調査で明らかに
つまり現在のWebでは、新しく生まれるページの多くにAIが関与している。
本サイトの場合、公開記事は約630本で、そのうち約500ページがインデックスされている。割合で言えばおよそ8割で、一般的なブログとしては特別低い数字ではない。それでもSearch Consoleのグラフを見ると、2026年に入ってからインデックス数は徐々に減少している。
重要なのは、ここに善悪の問題だけでは説明できない構造があるという点である。
AIを使えば、コンテンツを生成すること自体は容易になる。
そして、そのコストが限りなく低くなれば、Web全体のページ数は自然と増えていく。
この状況は、検索エンジンにとって新しい課題を生む。
Webページが爆発的に増えるとき、検索エンジンはそのすべてを処理し続けることができるのだろうか。
第2章 検索エンジンの「3つのコスト」
検索エンジンは、単にWebページを集めて並べているわけではない。
その裏側では、大きく三つの処理が行われている。
クロール
↓
インデックス
↓
ランキング
まず、クロール。
GooglebotなどのクローラーがWebサイトを巡回し、新しいページや更新されたページを発見する。
次に、インデックス。
収集されたページは解析され、検索用の巨大なデータベースに登録される。
そして最後がランキング。
ユーザーが検索したとき、どのページをどの順番で表示するかを決定する。
この三つの処理は、それぞれ膨大な計算資源を必要とする。
クロールにはネットワーク帯域と巡回時間が必要になる。
インデックスには巨大なストレージと解析処理が必要になる。
ランキングにはリアルタイムの計算が必要になる。
つまり検索エンジンは、実は巨大なインフラの上に成り立っている。
もしWebページの数がゆっくり増えているのであれば、この仕組みは問題なく機能する。
しかし、ページ数が急激に増加した場合、事情は変わる。
クロールすべきページが増える。
インデックスに登録するページも増える。
検索時に評価すべき候補ページも増える。
結果として、検索エンジンの負荷は大きくなる。
特にインデックスは、検索エンジンの中核にある資産でありながら、同時にコストの大きい部分でもある。
すべてのページを保存し、解析し、検索可能な状態で維持するためには、膨大な計算資源が必要になるからだ。
もしAIによってWebページの数が急激に増えたとしたら、検索エンジンは一つの選択を迫られる。
すべてを保存し続けるのか。
それとも、どこかで整理を行うのか。
第3章 Googleが始めた「Index Cleansing」
Search Consoleを観察していると、興味深い現象に気付くことがある。
公開されているページ数に対して、
インデックスされているページ数が減っていく。
そしてその代わりに増えていくのが、次のような状態のページだ。
・クロール済み – インデックス未登録
・検出 – インデックス未登録
・代替ページ
・重複ページ
つまり、Googleはページを発見しているにもかかわらず、
あえてインデックスに登録していないケースが増えている。
これは一見すると不可解に見える。
なぜ検索エンジンは、見つけたページを登録しないのだろうか。
しかし第2章で見たように、検索エンジンにはクロール・インデックス・ランキングという三つの処理が存在する。
そしてその中でも、インデックスは最もコストのかかる部分の一つだ。
すべてのページを保存し続けることは、技術的には可能かもしれない。
しかしそれが検索品質の向上につながるとは限らない。
もし同じような内容のページが大量に存在した場合、
インデックスが膨張するだけで、検索結果の品質はむしろ下がる可能性がある。
そのためGoogleは、かなり以前から
「価値のあるページだけをインデックスに登録する」
という方針を取ってきた。
AIコンテンツが急増した現在、この選別はさらに厳しくなっている可能性がある。
SEOコミュニティでも
・新しいページがインデックスされにくくなった
・クロールはされるが登録されない
・インデックス数が減少している
といった報告が増えている。
もちろん、これは公式に「インデックス削減が行われている」と発表されたわけではない。
しかしSearch Consoleの観測データを見る限り、
インデックスの整理が進んでいる可能性は十分に考えられる。
この動きは、ページを罰しているというよりも、
検索エンジン全体の品質を維持するための整理と見る方が自然だろう。
いわば、巨大化したインデックスの中から
検索にとって重要なページを選び直す作業である。
しかしここで、もう一つ興味深い疑問が生まれる。
もしインデックスが減っているのなら、
サイトのアクセスも減るはずではないだろうか。
実際には、必ずしもそうとは限らない。
第4章 インデックスが減ってもアクセスが減らない理由
インデックス数が減ると聞くと、多くの人はこう考える。
ページが減る
= 検索流入も減る
しかし実際のデータを見ると、必ずしもそうとは限らない。
インデックスが減っているにもかかわらず、検索流入が大きく変わらない、あるいはむしろ増えるケースも報告されている。
この現象は、検索エンジンの評価の仕組みを考えると説明できる。
サイトのすべてのページが同じ価値を持っているわけではない。
検索結果からアクセスを集めているページは、実際にはサイトの一部に集中していることが多い。
例えば
・検索意図に強く一致する記事
・長期間読まれている記事
・専門性の高い記事
こうしたページが、検索流入の大部分を担っている。
一方で、ほとんど読まれていないページも存在する。
重複した内容や、検索需要の少ないテーマの記事などがそれにあたる。
もしGoogleがインデックスの整理を行った場合、
こうしたページが検索インデックスから外れる可能性がある。
しかし、それらのページはもともと検索流入への寄与が小さい。
そのためインデックス数が減っても、アクセス数には大きな影響が出ない場合がある。
むしろ、インデックスが整理されることで、
サイト全体の評価がより明確に伝わる可能性もある。
検索エンジンにとって重要なのは、
「ページ数」ではなく「検索に対する価値」だからだ。
結果として
インデックス数
↓
検索流入
→ または ↑
という現象が起きることもあり得る。
この変化は、単にページが削除されたというより、
サイトの中で
重要なページがより強く評価される
ようになったとも解釈できる。
しかし、ここで別の疑問が浮かぶ。
もしAIによってコンテンツが増えているのだとすれば、
その責任は誰にあるのだろうか。
第5章 AI Slopは誰の責任なのか
近年、SEOや検索の議論の中でよく聞かれる言葉がある。
AI Slop
生成AIによって量産された、価値の低いコンテンツを指す言葉だ。
同じような内容の記事。
表面的なまとめ。
検索結果を焼き直しただけのページ。
こうしたコンテンツが増えたことで、Web全体の情報密度が下がっているという指摘もある。
そのため、AI Slopの問題はしばしば
・AIユーザーの問題
・SEO業者の問題
・コンテンツ農場の問題
として語られる。
しかし、この現象を少し引いて見ると、もう少し構造的な側面が見えてくる。
生成AIの登場によって、
コンテンツ生成のコストは大きく下がった。
数千文字の記事を書くことは、かつては数時間の作業だった。
現在では、数秒で生成することもできる。
この変化は、人間のモラルだけでは説明できない。
コストが下がれば、
コンテンツの量は自然に増える。
これは技術の歴史の中で何度も起きてきた現象だ。
例えば
印刷技術の普及
→ 書籍の爆発的増加
インターネットの普及
→ Webページの急増
生成AIも、同じ流れの中にある。
つまりAI Slopは、単なる不正行為というより
技術進化が生んだ副作用
とも言える。
さらに興味深いのは、この生成AIの発展を支えている企業の中に、
Google自身も含まれているという点だ。
Googleは検索エンジンの運営者であると同時に、
生成AIの開発者でもある。
その意味で、現在起きている状況は
誰かの悪意というより、
技術の進化と検索インフラの間で生まれたジレンマ
に近い。
Webのページ数は増え続ける。
しかし検索エンジンは、すべてを保存し続けることはできない。
その結果として起きているのが、
インデックスの整理という動きなのかもしれない。
では、AI時代の検索エンジンは、
どのようなコンテンツを残そうとしているのだろうか。
第6章 AI時代に残るコンテンツとは何か
生成AIの登場によって、Web上のコンテンツはこれまで以上の速度で増え始めている。
記事を書くこと自体は、もはや技術的に難しいことではない。
AIを使えば、一定水準の文章を生成することは誰でも可能になった。
しかし、検索エンジンが評価する価値は、必ずしも文章量ではない。
むしろAIコンテンツが増えるほど、検索エンジンは
信号とノイズの区別
を強めていく必要がある。
同じような内容の記事が大量に存在する状況では、
検索エンジンにとって重要なのは
「ページ数」ではなく
「情報としての密度」
だからだ。
その結果、AI時代の検索では、次のようなコンテンツが相対的に価値を持ちやすくなる。
実験
観察
体験
一次情報
つまり、実際に時間をかけて得られた情報である。
AIは文章を生成することができる。
しかし、現実の出来事を体験することはできない。
試してみた結果。
失敗した記録。
現場で得た知見。
そうした情報には、必ず人間の時間が刻まれている。
検索エンジンが最終的に評価しているのは、
こうした
時間の痕跡
なのかもしれない。
インデックス数が減るという現象は、一見するとネガティブに見える。
しかしそれは、検索が衰退しているというより
検索が選別を強めている
とも解釈できる。
AIによってコンテンツが増え続ける時代だからこそ、
検索エンジンは
「どのページを残すか」
という判断を、これまで以上に慎重に行うようになる。
そしてこの変化は、もう一つの問題にもつながっていく。
生成AIの多くは、
検索インデックスを知識源としている。
もし検索インデックスに時間差や構造的な制約があるとしたら、
AIの回答にも影響が出ることになる。
最終章 検索インデックスというAIの知識基盤
生成AIの議論では、しばしばモデルそのものの性能に注目が集まる。
どのモデルが賢いのか。
どのベンチマークで高いスコアを出しているのか。
しかし実際には、AIの回答品質は
モデルの知能だけで決まるわけではない。
AIが参照する知識の基盤もまた、同じくらい重要な要素になる。
現在、多くの生成AIは
学習データ
検索インデックス
外部情報(RAG)
といった複数の情報源を組み合わせて回答を生成している。
その中でも検索インデックスは、Web上の情報を体系的に整理した巨大な知識基盤と言える。
もしこのインデックスの構造に変化が起きれば、
AIの回答にも影響が及ぶ可能性がある。
例えば
・クロールの頻度
・インデックスの更新速度
・登録されるページの選別
といった要素は、検索エンジンだけでなく、
その上に構築されるAIシステムの振る舞いにも関係してくる。
今回見てきた「インデックスの整理」という動きも、
単なるSEOの問題ではなく、
AI時代の知識インフラ
という視点から考える必要があるのかもしれない。
検索エンジンがどの情報を残し、どの情報を外すのか。
その判断は、これからのAIの知識にも影響を与えていく。
次の記事では、この点をもう少し具体的に見ていく。
Geminiはなぜ賢いのに間違えるのか。
検索インデックスの構造と、生成AIのハルシネーションの関係を整理してみたい。




