
![OpenAIのひとつの回答[Cerebras]──Codex Sparkが示す「速さ」への執念](https://b.aries67.com/wp-content/uploads/2026/02/openai-cerebras-codex-spark-speed.webp)
序章:チップの大きさに笑う。でも、話の主役は「速さ」だ
半導体の世界で、「チップの大きさ」を売り文句にする日が来るとは思わなかった。
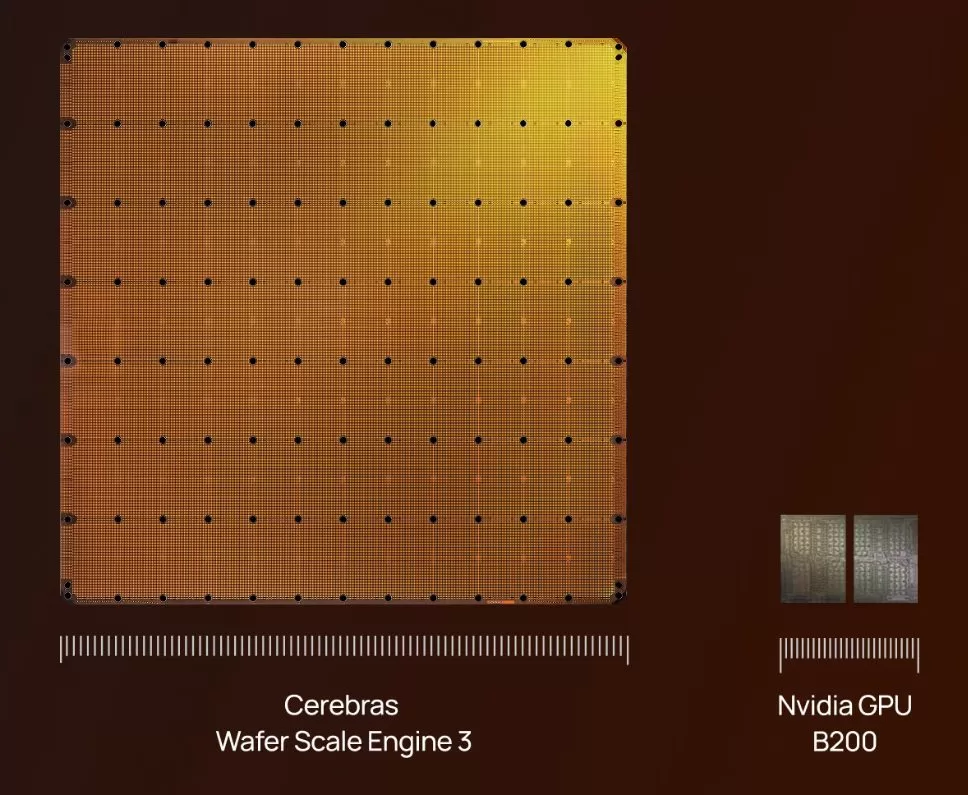
Cerebras の Wafer Scale Engine 3――ウエハーを丸ごと1枚、切らずにそのまま“チップ”にしたという代物――の写真を見たとき、多くの人はまず笑うだろう。隣に置かれた NVIDIA の最新 GPU と比べても、スケール感が完全にバグっている。冗談か、あるいは展示会向けのジョークに見えるかもしれない。
https://www.cerebras.ai/chip
だが、今回の話の主役は「でかいチップ」ではない。主役は、速さだ。
OpenAI が発表した GPT-5.3 Codex Spark は、「賢くなった」ことよりも、「待たせない」ことを正面から売りにしている。毎秒1000トークン級という数字は、ベンチマークの誇示というより、開発者の作業テンポそのものを変えるための宣言に近い。
実際、コーディング支援という用途は、AIの賢さよりも「間」を嫌う。差分の生成、テストのひな型、リファクタの提案――これらは、数秒待たされるだけで思考の流れが切れる。Codex Spark が狙っているのは、その“待ち時間”を消すことだ。新しいモデルというより、新しい使い心地を作りにきている、と言ったほうが近い。
そして、その裏側に選ばれた計算機が、Cerebras という少し奇妙な選択肢だった。
Cerebras は「世界最大のAIチップ」「GPUクラウドより何倍も速い」といった景気のいい言葉を並べている(と彼らは言っている)。もちろん、そこには条件付きの数字やマーケティングの匂いもある。それでも、少なくとも一つだけ確かなことがある。OpenAI は“速さ”という体験を優先するために、GPUの延長線とは違う答えを取りに行った、という事実だ。
この文章は、NVIDIAの時代が終わる、という話ではない。GPUはこれからも主役であり続けるだろう。だが同時に、AIが「どんなモデルか」だけでなく、「どんな計算機で動くか」まで含めて設計される段階に入りつつある、という兆しでもある。
Codex Spark と Cerebras は、その変化が初めて“実用品の形”で現れた一例に過ぎない。
チップの大きさに笑ってからでいい。だが本当に見るべきなのは、その奥にある「速さへの執念」だ。ここから先、AIはもう少しだけ、待たない道具に近づいていく。
第1章:Codex Sparkは何を変えたのか――1000 tok/sの意味
毎秒1000トークン。
この数字を聞いても、正直なところ多くの人はピンと来ないはずだ。モデルの性能表に並ぶ数値のひとつ、くらいの印象で終わるかもしれない。だが、Codex Spark が狙っているのは「速いモデルです」というアピールではない。作業のテンポを変える、という一点に尽きる。
コーディング支援の現場では、AIの賢さはすでに十分に高い水準にある。問題は、返ってくるまでの“間”だ。差分を投げて修正案を待つ。テストの雛形を頼んで数秒待つ。リファクタの提案を求めて、また少し待つ。この「少し」が積み重なると、思考の流れは簡単に途切れる。人間は案外、待つのが下手な生き物だ。
Codex Spark は、その「待ち時間」をできるだけ感じさせないところに照準を合わせている。1000 tok/s という数字は、ベンチマークとしての誇示というより、“待たせない”ことを保証するための余裕のようなものだ。ストリーミングで文字が流れてくる速度が速い、という話ではない。こちらが考えをまとめている間に、向こうの答えがすでに出揃っている、という感覚に近い。
ここで重要なのは、Codex Spark が「より賢く考える」方向には振っていないことだ。むしろ逆で、マルチモーダル対応を切り捨て、テキストに割り切り、設計全体を即応性のために最適化している。128k のコンテキストウィンドウも、無制限に何でも放り込める魔法の箱ではない。必要な情報を切り出して投げる前提の、実務的なサイズだ。
この割り切りは、プロダクトとしての性格をはっきりさせている。Codex Spark は「じっくり考える相棒」ではない。手の速い相棒だ。差分を投げれば即座に返る。テストを書けと言えば、ほぼ待たずに雛形が出てくる。思考の流れを止めずに、次の一手に進める。この体験の変化こそが、1000 tok/s という数字の正体だ。
言い換えれば、これはモデルの性能競争ではない。道具としての手触りの話である。どれだけ賢いか、ではなく、どれだけ邪魔をしないか。Codex Spark は、AIを「相談相手」から「作業の延長」に近づけるために作られている。
そして、その“速さ優先”という設計思想を、実際のプロダクトとして成立させるために、OpenAI は計算機の選び方そのものを変えた。ここから先の話は、なぜ GPU の延長線ではなく、Cerebras という少し風変わりな選択肢が出てきたのか、という話になる。
第2章:「3000 tok/s(Cerebras公式)」という実感のある数字
Codex Spark が毎秒1000トークン級の応答を目指している、という話だけでも十分に速い。だが、Cerebras の公式サイトを覗くと、さらに景気のいい数字が踊っている。
「OpenAI の GPT OSS 120B で 3000 tok/s 超。主要な GPU クラウドの 15 倍」――もちろん、これは “とCerebrasは言っている” という前提付きの話だ。条件付きのピーク値だろうし、比較条件の取り方にもマーケティングの匂いはする。
それでも、この数字が面白いのは、「速い」という抽象的な主張ではなく、サイズ感の分かるモデル名と一緒に提示されている点にある。120B クラスのモデル、と言われると、多くの人は「それなりに重たい」「普通に回すと待たされるやつ」という感触を持っているはずだ。そのクラスで 3000 tok/s という主張は、話半分で聞くにしても、「ああ、狙っている世界が違うな」という実感を与えるには十分だ。
ここで、Codex Spark の 1000 tok/s という数字が、別の意味を帯びて見えてくる。
Cerebras 側が掲げる 3000 tok/s は、いわば アーキテクチャの到達点のデモ に近い。一方で Spark の 1000 tok/s は、可用性や安定性、プロダクトとしての現実的な運用を含めた “実用品の着地点” と考えるほうが自然だ。つまり、両者は同じ土俵で殴り合っているわけではない。
重要なのは、どちらの数字が正確か、ではない。
「このクラスのモデルを、ここまでの速度で“道具として”扱おうとしている」という方向性そのものだ。従来の GPU クラスタ型の推論では、120B クラスは“それなりに待つもの”という前提があった。その前提を壊しに行く、という意志が、この手の数字にははっきりと表れている。
言い換えれば、ここで起きているのは「何トークン出るか」の競争ではない。“待つのが当たり前”という感覚を壊せるかどうか、という競争だ。Spark の 1000 tok/s も、Cerebras の言う 3000 tok/s も、その文脈で見ると、単なるベンチマークの数字以上の意味を持ってくる。
そして、その「待たない世界」を現実のプロダクトに落とし込むために、OpenAI は GPU の延長線とは少し違う方向に舵を切った。次の章では、なぜそういう選択が必要になったのか、もう少し計算機側の事情から見ていくことにしよう。
第3章:なぜGPUではなく、こんな計算機が必要になったのか
まず前提として、GPUは今でもAI計算の王者だ。学習でも推論でも、エコシステムの厚みと汎用性は他の追随を許さない。ここで語りたいのは「GPUはもうダメだ」という話ではない。むしろ逆で、GPUがあまりに万能すぎるがゆえに、別の最適解が欲しくなる場面が見えてきた、という話だ。
従来の大規模推論は、基本的に「小さなチップをたくさん並べて、ネットワーク越しに協調させる」発想で作られてきた。これはスケールさせるには理にかなっている。モデルが大きくなればノードを足せばいいし、クラウド事業者にとっても運用しやすい。だが、この構成には避けられないコストがある。データの移動と調停だ。
モデルが大きくなるほど、メモリは分散し、計算は分割され、結果は集約される。そのたびに、ネットワーク越しの通信や同期が入る。バッチ処理やオフライン推論なら、それでもいい。多少のレイテンシはスループットで殴れるからだ。だが、Codex Spark が狙っているのは、そういう世界ではない。
リアルタイムのコーディング支援では、“待たせないこと”そのものが価値になる。数秒の遅延は、単なる遅さではなく、思考の流れを切るノイズになる。ここでは、スループットよりも、予測可能で短い応答時間のほうが重要になる。分散構成はスケールには強いが、この「待ち時間を削る」という目的には、必ずしも最短距離ではない。
だからといって、GPUが悪いわけではない。GPUは「何でもそこそこ速くできる」ことに最適化された、非常に優秀な汎用エンジンだ。ただし、用途が“低レイテンシ至上主義”に振り切れたとき、汎用性はときに足かせにもなる。ここで初めて、「用途に特化した計算機」という発想が現実味を帯びてくる。
TPUや Groq、そして Cerebras は、この文脈の中で見ると分かりやすい。いずれも「GPUの代わり」になろうとしているわけではない。GPUでは行きにくい領域を、別の設計思想で取りに行っているだけだ。Codex Spark が要求しているのは、まさにその“別の領域”に属する性質のもの――すなわち、速く、予測可能で、思考を邪魔しない応答だ。
OpenAI が Cerebras という少し風変わりな選択肢に目を向けたのは、奇をてらったからではない。「速さ」を体験として成立させるために、計算機の前提から見直す必要が出てきた、それだけの話だ。次の章では、その Cerebras がどんな思想でこの問題に答えようとしているのか、もう少し踏み込んで見ていこう。
第4章:Cerebras WSE-3という「物理で殴る」設計思想
Cerebras の Wafer Scale Engine 3 を初めて見た人の多くは、たぶん同じ感想を持つ。「これはチップなのか?」と。
半導体の世界では、ウエハーは切り分けるものだ。小さなダイに分割し、欠陥があればその部分だけを捨てる。歩留まりとコストの現実を考えれば、これは長年かけて最適化されてきた“常識”でもある。

https://www.cerebras.ai/chip
Cerebras は、その常識を正面から無視した。
切らない。分けない。ウエハー1枚を、そのまま1つのチップとして使う。
結果として生まれたのが、WSE-3 という「世界最大のAIチップ(と彼らは言っている)」代物だ。サイズもトランジスタ数も、GPUの延長線で考えると、ほとんど冗談のようなスケールになる。
もちろん、これは「でかいから偉い」という話ではない。Cerebras が本当にやりたいのは、分散しない計算機を作ることだ。GPUクラスタでは、モデルもメモリも計算も分割され、結果はネットワーク越しにやり取りされる。そこには必ず通信と同期のコストが入り込む。WSE-3 は、その前提を物理的に壊しに行っている。
ウエハー1枚が1つの計算機であれば、メモリも計算も通信も、すべてチップの中で完結する。外に出さない。束ねない。調停しない。「全部ここでやる」という、極端に単純な設計思想だ。これは、分散コンピューティングの常識に対する、かなり力技なカウンターでもある。
当然、こんな設計が簡単に成り立つはずはない。最大の敵は、歩留まりだ。ウエハーサイズが大きくなればなるほど、どこかに欠陥が当たる確率は跳ね上がる。普通なら「だからやらない」で終わる話だ。Cerebras はそこで引き返さなかった。欠陥がある前提で設計し、死んだ部分を避けて回す、というソフトウェアとハードウェアの合わせ技で、この無茶な構成を成立させている。
言い換えれば、彼らは「完璧な1枚」を作ろうとしているのではない。「使える部分を寄せ集めて、1つの巨大な計算機として成立させる」ことをやっている。RAID が壊れたディスクを無視して動き続けるのと、発想としては少し似ている。それを、シリコンの1枚の中でやっている、というだけだ。
こうした設計の狙いは明確だ。分散によるオーバーヘッドを、物理的に消す。
その結果として得られるのが、予測可能で、短く、安定したレイテンシだ。スループットを積み上げるための計算機ではなく、「待たせない」ための計算機。WSE-3 は、そのために作られた、かなり偏った答えだと言っていい。
もちろん、Cerebras の掲げる性能値や比較表は、話半分で見るべきだろう。条件付きのピーク値も含まれているはずだし、「世界最大」「何倍速い」といった言い回しには、マーケティングの匂いも強い。だが、それを差し引いても、「分散しない」という一点にここまで振り切った計算機が、実際にプロダクトとして使われ始めているという事実は、無視できない。
Codex Spark が要求している「速さ」は、こうした極端な設計思想と、きれいに噛み合っている。次の章では、Cerebras だけでなく、TPU や Groq といった他の“別解”も並べて見ながら、AIインフラがどこに向かい始めているのかを整理してみよう。
第5章:変態ハード列伝――TPU / Groq / Cerebrasという分岐点
Cerebras の WSE-3 は、たしかに見た目のインパクトが強い。だが、これを「変わり種の珍品」として片付けてしまうと、少し大事なものを見落とす。実際には、同じ時代の空気の中から、似た方向性を持つ“別解”がいくつも生まれている。
代表的なのが、Google の TPU と Groq だ。
TPU は、いわば 巨大インフラ前提の専用化 という答えだ。汎用GPUの上にソフトウェアで最適化を積み上げるのではなく、最初から「この用途に最適な回路」を前提に設計し、データセンター規模で運用する。スケールと運用を含めてひとつの“計算機”として考える、クラウド時代らしいアプローチと言っていい。
Groq は、方向性がまったく違う。こちらは レイテンシ至上主義 に振り切っている。分岐を減らし、スケジューリングを排し、命令を決め打ちのパイプラインで流す。柔軟性は犠牲にする代わりに、応答時間をほぼ物理法則のレベルまで読み切れる設計だ。AI推論を「巨大な回路」として扱う、かなりストイックな答えである。
そして Cerebras は、物理サイズで分散を殴り倒す という、また別の方向に振り切った。小さなチップを束ねるのではなく、最初から「束ねなくて済む大きさ」を作ってしまう。分散による通信や同期のコストを、設計思想ごと消しに行くアプローチだ。
三者に共通しているのは、どれも GPUの延長線にいない という点だ。いずれも「GPUを置き換える」ことを主目的にしているわけではない。むしろ、GPUでは取りにくい性質――低レイテンシ、予測可能性、用途特化――を、別の設計で取りに行っている。
ここまで来ると、これは個別企業の奇抜な挑戦というより、AIインフラ全体が分岐し始めている兆候と見るほうが自然だろう。学習、バッチ推論、リアルタイム推論、エージェント的なワークロード――それぞれで、求められる性質は少しずつ違う。その違いを、ソフトウェアの工夫だけで吸収するのではなく、計算機の形そのものを変えて対応する、という選択肢が現実味を帯びてきた。
Codex Spark は、その分岐の一端を、プロダクトという形で見せている。
「速さ」という体験価値を優先した結果、選ばれたのが Cerebras だった。それは、たまたま奇妙なハードを使ってみた、という話ではない。用途から逆算して、計算機の前提を選び直した、というだけの話だ。
この流れは、GPUの時代が終わることを意味しない。むしろ逆で、GPUはこれからも広い領域で主役であり続けるだろう。ただし同時に、AIは“ひとつの計算機の形”で全部をまかなう時代を抜けつつある。その兆しが、TPUやGroq、そしてCerebrasという「変態的な答え」の並び方に、はっきりと表れている。
次の章では、この話をもう一度 OpenAI 側の視点に戻し、Codex Spark というプロダクトが何を意味しているのか、少し引いたところからまとめてみよう。
コラム:Data Sheet から読み解く Wafer Scale Engine 3
Wafer Scale Engine 3 Data sheet
Cerebras のデータシートを眺めると、まず目に入るのは「125 PetaFLOPs」「900,000 コア」といった、いかにも景気のいい数字だ。だが、Wafer Scale Engine 3(WSE-3)の正体を理解するうえで、本当に注目すべきなのは演算性能そのものよりも、帯域の数字だろう。
資料には、21 PB/sec のメモリ帯域、214 PB/sec のコア間帯域といった値が並んでいる。これは単に「速い」というレベルの話ではない。発想としては、計算を速くする以前に、データを動かさなくて済む構造を作るという方向に振り切っている。GPU クラスタがネットワーク越しの通信や同期と戦い続けてきたのに対し、Cerebras はその問題をトポロジー(配置)ごと物理で潰しに行っている、と言ったほうが近い。
メモリ構成も、その思想をよく表している。オンチップには 44GB、さらに外部には最大 1,200TB までのモデルメモリを接続できる構成になっており、資料には「重みは並列にストリーミングされる」と明記されている。つまり、巨大モデルをすべて常駐させる前提ではなく、必要な重みを高速に流し込みながら計算する設計だ。分割して配るのではなく、1枚の“脳”に食わせるという発想に近い。
900,000 というコア数も、単に並列度を誇示するための数字ではない。コア間帯域の太さとセットで見ると、これはむしろ、計算ユニット同士をできるだけ“近所”に置くための密度だと分かる。ネットワーク越しに話をさせる代わりに、シリコンの上で直接やり取りさせる。そのための数であり、そのための配置だ。
冷却やクラスタ構成の記述も、地味だが重要だ。液冷・空冷の両対応、冗長ポンプ構成、専用のメモリ拡張ユニットやスイッチ群。これは研究室の実験機ではなく、データセンターに置いて継続運用する前提の“商品”として設計されていることを示している。見た目は変態的でも、狙っているのはきわめて実務的な領域だ。
資料には「大規模言語モデルのトレーニングを支援する」といった表現もあるが、読み取れる本質は別のところにある。WSE-3 は「何でもできる汎用計算機」ではない。巨大なテンソル計算を、できるだけ分散せず、できるだけ低レイテンシで回すための計算機だ。その意味で、これは「速い GPU」ではなく、精度を保ったまま巨大モデルを扱うための、超巨大な NPUに近い存在だと言っていい。
数字の一つ一つを鵜呑みにする必要はない。だが、データシート全体から浮かび上がってくる設計思想ははっきりしている。Cerebras は、性能競争の延長線で戦っているのではない。分散という前提そのものを、物理サイズと帯域でひっくり返そうとしている。WSE-3 は、そのための、かなり極端で、しかし一貫した答えなのだ。
終章:これはNVIDIAの終わりではない。体験設計の始まりだ
ここまで読んで、「GPUの時代は終わるのか」と感じた人もいるかもしれない。だが、この話はそういう単純な構図ではない。GPUはこれからも、学習でも推論でも、AI計算の中心であり続けるだろう。エコシステムの厚み、汎用性、運用のしやすさ――それらは、他のどんな選択肢も簡単には置き換えられない。
Codex Spark と Cerebras の話が示しているのは、GPUが不要になる未来ではない。
GPUだけでは足りなくなる用途が、はっきり見え始めたということだ。
Codex Spark は、賢さを誇示するモデルではない。マルチモーダルも切り捨て、コンテキストも無限ではない。その代わりに、「待たせない」という一点に、設計の重心を置いた。差分が即座に返る。テストの雛形が思考を遮らない。AIが“相談相手”ではなく、作業の延長に近づく。その体験の変化こそが、Spark の売り物だ。
そして、その体験を成立させるために、OpenAI は計算機の前提から選び直した。
GPUクラスタの延長線ではなく、分散しないという極端な設計思想を持つ Cerebras を使う。そこには、「速さ」を単なる性能指標ではなく、プロダクトの価値そのものとして扱う姿勢が見える。
Cerebras の掲げる数字は、話半分で聞くべきだろう。「世界最大」「何倍速い」といった言い回しには、いつの時代もマーケティングの匂いがつきまとう。それでも、少なくとも一つだけ確かなのは、OpenAI が“速さの体験”のために、GPUの延長線とは違う答えを取りに行ったという事実だ。
TPU、Groq、そして Cerebras。これらはどれも、GPUの代替ではない。GPUでは取りにくい性質を、別の設計で取りに行くための分岐だ。学習、バッチ推論、リアルタイム推論、エージェント的ワークロード――用途ごとに最適な計算機を選ぶ、という発想は、もはや特別なものではなくなりつつある。
言い換えれば、AIの進化は、もはやモデルの中だけで完結しない。
どんな計算機で動かすか、という選択そのものが、体験を決める時代に入ってきた。
Codex Spark は、その変化を最初に“触れる形”で見せてくれたプロダクトのひとつだ。
Cerebras は、そのための、少し奇妙で、かなり極端な道具に過ぎない。
チップの大きさに笑うのは、たぶん正しい反応だ。
だが、その裏で起きているのは、「AIはどう設計されるべきか」という問いが、ソフトウェアからハードウェアまで含めて引き直されているという、わりと大きな変化でもある。
OpenAIのひとつの回答は、たしかに「速さ」だった。
そしてそれは、AIが“賢くなる物語”の次に来る、“使い心地が変わる物語”の始まりを告げているのかもしれない。
参照


