

導入
GPUの性能競争は、まだ続いているように見える。
だが、その勝敗はすでに決している。
いま起きているのは、まったく別の戦いだ。
それは「どれだけ速く計算できるか」ではない。
「どれだけ速く繋げるか」という戦いである。

NVIDIAが発表したVera Rubin NVL72は、その転換点を明確に示した。
これはGPU製品ではない。
“構造”そのものの変化だ。

Vera Rubin NVL72は“GPU”ではない
72基のGPU。
36基のCPU。
さらに、DPU、SuperNIC、NVLinkスイッチが一体化されている。
この構成を見た時点で、従来の理解は通用しない。
1ラック=1台のAIスーパーコンピュータ
もはや単体GPUのスペック比較に意味はない。
重要なのは、それらがどう連携するかだ。
異常なスペックの意味
公開されているスペックは確かに異様だ。
- 推論:3,600 PFLOPS
- HBM帯域:20.7TB
- NVLink帯域:260TB/s
だが、この数字を単純に「速い」と受け取ると本質を見誤る。
ここで問われているのは性能ではない。
それをどう繋ぐか
である。
NVLink 6 ─ 主役は通信になった
NVLink 6の帯域は260TB/sに達する。
このシステムの本体はGPUではない。
260TB/sの“接続”である。
つまり、GPUはもはや主役ではない。
これはもはや単なる内部バスではない。
ネットワークそのものだ。
この帯域設計は、もはや「チップ」ではなく「ネットワーク機器」の発想に近い。
GPUは単体の演算装置ではなく、ノードとして扱われる。
NVLinkはそれらを結ぶファブリックとなる。
構造は完全に分散システムへと移行した。
コラム:昔からボトルネックは変わらない
PCでも同じことが起きていた。
CPUのクロックが上がっても、
体感速度を決めるのはメモリだった。
かつてはL2キャッシュを増設することで、
わずか数十KBの違いでもレスポンスは向上した。
処理そのものはCPUが律速でも、
“体感”はデータの出入りで決まる。
この構造は、今のAIでも変わっていない。
違うのはスケールだけだ。
銅線の復権 ─ ACC規格が意味するもの
ここでさらに興味深い動きがある。
Active Copper Cable(ACC)の標準化だ。
ケーブル内部に信号補正用のICを組み込み、
高速通信でも減衰を抑える。
Ethernetのリピーターのようなものだが、
ケーブル内蔵でやっていることは高度だ。
つまりこうなる。
ケーブルは“受動部品”ではない
回路の一部である。
なぜ光ではなく銅なのか。
理由はシンプルだ。
- 低コスト
- 低遅延
- ラック内では十分な帯域
近距離では、銅のほうが合理的なのだ。

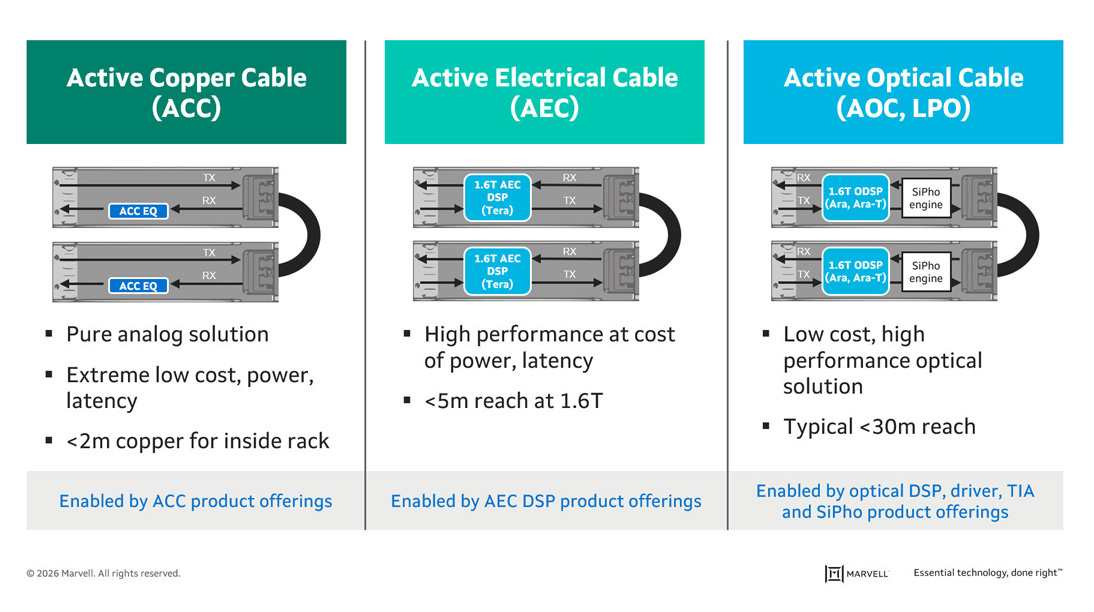
この図を見ると、銅線の進化が一目で分かる。
従来のDACは、ただの“導線”だった。
距離が伸びれば信号は劣化し、速度の限界があった。
しかしACCでは違う。
ケーブルの中に回路が入る
信号補正を行うことで、銅線でありながら高速通信を維持する。
さらにAECでは、DSPを内蔵し、より長距離・高性能を実現する。
この図の本質は、単なる比較ではない。
重要なのはここだ。
配線が“受動部品”ではなくなった
これは設計思想の転換である。
Vera Rubin NVL72が採用している構造は、
まさにこの方向性の延長線上にある。
- NVLinkの帯域拡張
- SmartNIC / DPU
- そしてACCの標準化
すべては同じ問題を解いている。
データをどう動かすか
ボトルネックの正体
AI処理の現場で起きている現象は明確だ。
GPUが遅いのではない。
通信が詰まる。
- データ転送待ち
- 同期待ち
- メモリアクセス待ち
すべては“移動”に起因する。
AIの速度 = 最も遅いリンク
この法則は、どれだけGPUを強化しても覆らない。
Groqは“別の答え”ではなく“追加装備”
Vera Rubin NVL72の構成をよく見ると、
Groq LPUは中核ではない。
オプションの推論アクセラレータ
という扱いになっている。
これは重要なポイントだ。
GroqはGPUの代替ではない。
GPUではカバーしきれない領域を補強する存在である。
- GPU:学習・汎用処理
- Groq:低レイテンシ推論
つまり、
“差し替え”ではなく“増設”
である。
特に、長文コンテキストやリアルタイム応答のような
推論負荷が極端に高い用途では、この構成が効く。
なお、公開直後ということもあり、
詳細ページが未整備な部分も見受けられる。
このあたりも含めて、まだ進行中のプロジェクトであることが分かる。
結論
Vera Rubinが示したものは明確である。
GPUの時代は終わっていない。
だが、主役ではなくなった。
これからの性能を決めるのは、
配線である
NVLink、DPU、NIC、そしてACC。
すべては「データをどう動かすか」のために存在する。
GPU戦争は終わった。
次に始まるのは──
インターコネクト戦争だ
あとがき
正直なところ、ここまで来ると「GPUが何TFLOPSか」は
あまり意味を持たなくなってきた。
配線、帯域、レイテンシ。
地味だが、逃げ場のない現実だ。
そして、それらがこれからの主役になる。
ここから先は、計算機ではなく通信の戦いになる。

