

GLM-5は総744B/アクティブ40Bというフロンティア志向のOSSモデルだが、実務の主役になれるかと言えば、立ち位置は微妙だ。mxGraphによる軽いテストとWeb生成の所感から、エージェンティックAI時代におけるフロンティアモデルの“別の価値”を考える。
第1章:GLM-5という“フロンティア志向OSS”の登場
GLM-5 が OSS として公開された、というニュースは、それなりにインパクトがあった。
総パラメータ数は約 7440 億、アクティブパラメータは約 400 億。MoE(Mixture of Experts)構成で、長大なコンテキストも扱える。設計思想から見ても、明らかに「軽量で手軽な実務モデル」とは別の方向、いわゆるフロンティア寄りの領域を狙ったモデルだ。

ここまで来ると、もはや「ローカルで気軽に回してみよう」という類の存在ではない。実際に触るとすれば、クラウド越し、あるいは提供されているホスト環境を通して、という形になるだろう。そうなると、自然に浮かぶ疑問がある。
結局、GPT や Gemini と何が違うのか?
派手な売り文句としては、「Word や Excel をネイティブに扱える」「複雑なドキュメント操作ができる」といった話も出てくる。確かにそれは面白いし、将来的な応用も想像しやすい。ただ一方で、それは“フロンティアモデルであること”の本質なのか、という点には少し距離を置いて考えたくなる。
いまの現場感覚で言えば、むしろ注目されているのは、軽量なモデルをツールや RPA と組み合わせて、いかに「仕事を卒なく回すか」という方向だ。エージェンティック AI という言葉が示す通り、主役は必ずしも巨大モデルそのものではなく、ワークフロー全体の設計に移りつつある。そうした流れの中で、GLM-5 のようなフロンティア志向のモデルは、どこに立つのか。正直、立ち位置は少し微妙にも見える。
だからこそ、今回はいきなり「すごい推論ができるか」といった派手な評価はしないことにした。代わりに、もっと地味で、もっとどうでもいいように見えるタスクを投げて、その“手触り”を見る。モデルの性格や作法は、こういうところに意外と滲み出るものだからだ。
フロンティア性能を測るには軽すぎるテストかもしれない。
それでも、「このモデルは、どういうアウトプットを“当たり前”として出してくるのか」を見るには、十分な材料になるはずだ。
了解。次からは H2 でいくね。
では、そのまま流れを受けて 第2章。
第2章:テスト方法──EOKに依存しない共通知識で“手触り”を見る
今回のテストは、最初から割り切っている。
フロンティア性能を測るためのベンチマークではないし、難問を解かせて推論力を競うつもりもない。見たいのは、もっと地味なところ、つまり「このモデルは、当たり前の仕事をどう整形して出してくるか」という手触りだ。
そこで題材に選んだのが、OSI 7階層参照モデル。
ネットワークをかじったことがある人なら誰でも知っている、時代にも流行にも左右されない共通知識だ。EOK(知識カットオフ)に依存しないし、最新情報の有無で差が出るテーマでもない。純粋に、「知っていることを、どう表現するか」を見るにはちょうどいい。
タスクは単純で、これを mxGraph で図解させる。
左に層、右に説明文、色分けしたボックスで見やすく配置する。いかにも教材にありそうな、ありふれた図だ。ここで見たいのは、正解を知っているかどうかではない。層名や順序が多少ズレたところで、本質はそこではない。
ポイントは三つある。
ひとつは、説明の粒度。
長すぎず、短すぎず、図の横に置くキャプションとして読めるか。教科書の丸写しになっていないか、逆に雑すぎて意味が抜け落ちていないか。
もうひとつは、整形の作法。
「○○層の説明:」といったテンプレ前置きに逃げず、普通の文章として置けているか。視線の流れを意識した配置になっているか。図として見たときに、うるさくないか。
そして最後が、無難さ。
変に欲張らず、破綻せず、エラーを出さず、「それなりにちゃんとしたもの」を出してくるかどうか。派手な工夫より、ここが一番モデルの性格を表しやすい。
実行環境は、chat.z.ai のお試しチャット。
特別なチューニングも、追加のツール指定もしていない。いわば、素の状態で「このモデルは、こういう指示にどう応えるのか」を見るだけのテストだ。

過去に同じ題材で gpt-oss でも試したことはある。ただし今回は、あくまで GLM-5 が主役で、gpt-oss は「このくらいは OSS でも普通にできる」という基準点としての存在に過ぎない。比較のために条件を増やしたり、タスクを捻ったりするつもりはない。同じ土俵で、同じくらいどうでもいい仕事をさせて、その出てきた“形”を見る。それで十分だ。
要するに、これは「賢さ」を測るテストではない。
仕事として出てくるアウトプットの癖を見るための、かなり意地の悪い、そして地味な試し方だ。
第3章:結果──派手ではないが、確かに“整っている”
まず結論から言うと、出てきたものは拍子抜けするほど地味だ。
「フロンティア級モデルの凄みが炸裂する」といった類の話ではない。OSI 7階層を図にする、というどうでもいいくらい平凡な仕事を、GLM-5 はごく普通にこなしてきた。それだけ、と言えばそれだけだ。
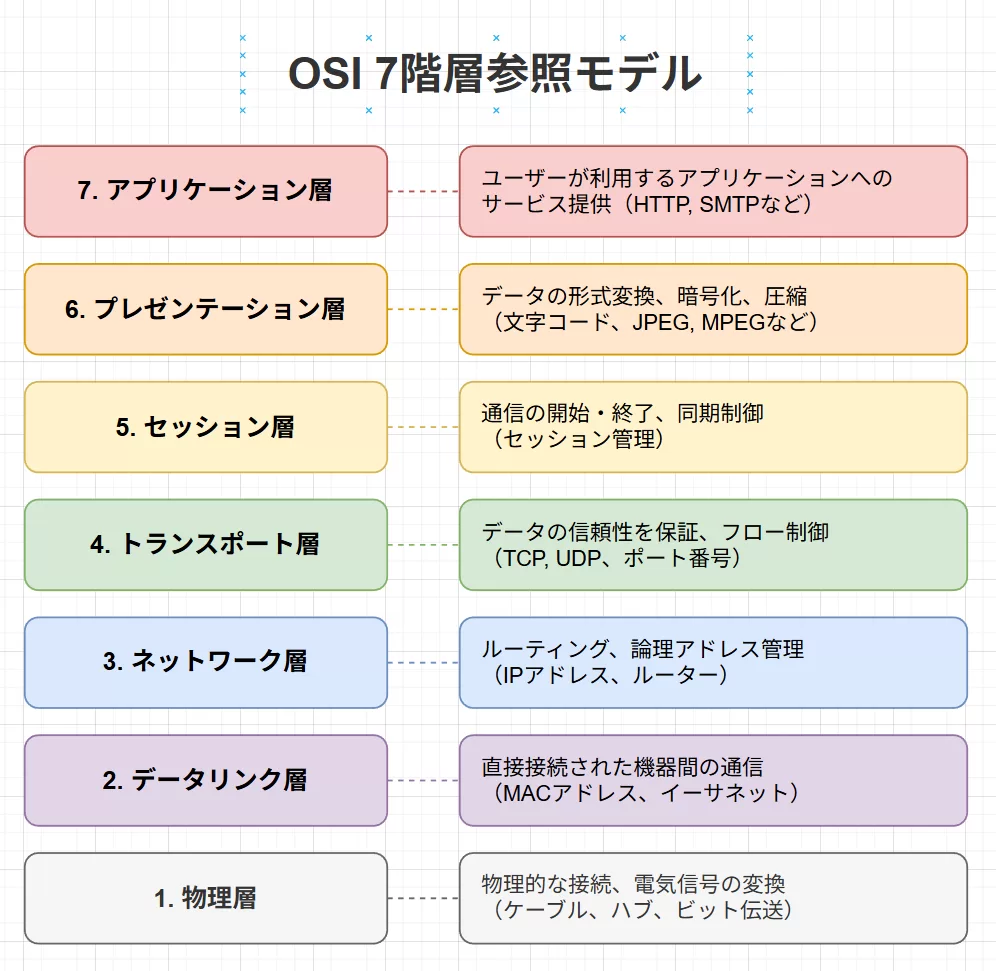
ただ、その「普通さ」の中身を見ると、少しだけ差が見える。
たとえば、各層の説明文。
HTTP や TCP といった具体例を自然に差し込みつつ、文章の長さは図のキャプションとしてちょうどいいところに収まっている。「○○層の説明:」といった機械的な前置きもなく、そのまま読める短文になっている。専門用語に寄りすぎず、かといって曖昧すぎるわけでもない。この手の図解に添える説明としては、かなり無難で、そして扱いやすい。
レイアウトも同様だ。
左に層、右に説明、色分けされたボックスで対応関係が分かる、という指示に対して、余計な装飾や無理な工夫を足さず、「それでいいよね」という形に素直に落としてくる。視線の流れも破綻していないし、図として見たときにうるさくもならない。
過去に同じ題材を gpt-oss で試したときと比べると、このあたりの“整形の癖”に違いが出る。gpt-oss の出力は、情報としては正しいが、「○○層の説明:」のようなテンプレ的な言い回しが入りがちで、少し教科書の抜き書き感が残る。一方、GLM-5 のほうは、説明文がもう少し“図の横に置く文章”として整えられている印象だ。
もちろん、これは革命的な差ではない。
20B クラスのモデルと、総パラメータ数で桁の違うフロンティア寄りのモデルを比べているのだから、どこかで差が出て当然とも言える。それでも、ここで見えているのは「難しいことができるか」ではなく、「当たり前の仕事を、どれだけ無難に、どれだけ扱いやすい形で出してくるか」という部分の違いだ。
このテストで分かるのは、せいぜいそこまでだ。
フロンティア性能の片鱗を見た、というよりは、アウトプットの整え方に一段階の余裕がある、という程度の話に近い。それでも、こういう地味な差は、実務で使うときの“手触り”に直結する。
派手さはない。
だが、「変にコケない」「変に欲張らない」「そのまま貼っても違和感が少ない」。GLM-5 の mxGraph 出力から受けた印象は、だいたいそんなところに落ち着く。
第4章:動物病院サイトHTMLの所感──単独評価として
もうひとつ、GLM-5 に投げてみたのが、動物病院のシングルページサイトの生成だ。
これは gpt-oss ではやっていないし、比較するつもりもない。あくまで単独評価として、「このモデルは、Web という文脈で何を出してくるか」を見るための素材だ。
条件を細かく縛ったわけではない。
プロンプト側で指定したのは、せいぜい「シングルページで、情報をひと通りまとめること」くらいのものだ。Web フォントの使用も、Tailwind CSS も、こちらからは指示していない。GLM-5 が「日本語サイトとして無難で正しそうな構成」を選んだ結果、そうなっただけだ。
実際、フォント選択も Noto Sans JP と Zen Maru Gothic という、これ以上ないほど無難な組み合わせになっている。つまりこれは、制約の産物というより、モデル自身が「日本語の実務サイトでは何が無難か」を知っていて、そこに寄せてきた結果と見るほうが自然だ。
出てきたコードは、おおむね 1000 行程度。
構成はシングルページで、診療案内、初診の流れ、FAQ、アクセスといった、いかにもそれっぽい情報が一通り並ぶ。日本語も無難で、変な言い回しは少ない。致命的なエラーもなく、少なくとも「ブラウザで開いて即崩れる」ようなものではない。全体としての印象は、「そつなくまとめてきた」という一言に尽きる。

正直に言えば、プロの現場でこのまま使える代物ではない。
デザインも情報設計も、要件定義も、ここから詰めるべきことはいくらでもある。実務では、これをそのまま納品して終わり、ということはまずあり得ない。ここだけの話、こういう“なんちゃってHTML”がペロッと出てきても、実際の仕事ではほとんど役に立たない場面のほうが多い。
それでも、この出力から見えるモデルの性格はある。
変に尖ったことをせず、無難な構成に寄せ、エラーを出さず、破綻しない形にまとめる。過剰に欲張らない代わりに、「最低限、それっぽいもの」をちゃんと形にする。mxGraph のテストで感じた印象と同じで、ここでも “整形の癖”が堅実寄りに出ている。
要するに、これは「すごいWebサイトを一発で作れる」という話ではない。
むしろ、「雑な指示でも、破綻しない叩き台を出してくる」という、かなり地味な能力の確認に近い。エージェンティック AI やワークフロー自動化の文脈で見るなら、こういう性格は確かに扱いやすい。一方で、フロンティアモデルに期待されがちな“何かを一気に変える魔法”とは、だいぶ距離がある。
この章で言いたいのは、それだけだ。
GLM-5 は、Web でも「卒なく、無難に、コケずに」まとめてくる。その性格は一貫している。だが、それはそのまま「実務の主役になれる」という意味ではない。あくまで、モデルの“作法”を覗き見た、という程度の話に留まる。
第5章:エージェンティックAI時代におけるフロンティアモデルの立ち位置
ここまで見てきた通り、GLM-5 の振る舞いは一貫して「無難に整える」方向に寄っている。mxGraph の図解でも、動物病院サイトの HTML でも、変に尖らず、破綻せず、「とりあえず使える形」に落とし込んでくる。この性格自体は悪くない。むしろ、日常的な作業を回す道具としては、かなり扱いやすい部類だ。
ただ、いまの流れを少し引いて見ると、気になる点もある。
最近の関心は、モデル単体の賢さよりも、「軽量なモデルをツールや RPA、ワークフローとどう組み合わせるか」という方向に明確に寄ってきている。いわゆるエージェンティック AI という文脈では、主役は巨大モデルそのものではなく、仕事を細かく分解し、外部の道具を呼び出し、結果をつなぎ合わせていく“段取りの設計”のほうだ。
この視点で見ると、フロンティア寄りの巨大モデルは、立ち位置が少し微妙になる。
日常業務の多くは、「軽くて速くて安定しているモデル」が、ツールと一緒に淡々と回してくれたほうが都合がいい。重いモデルを呼び出して、長い応答を待つ必然性は、実はそれほど多くない。実務的には、「そこそこ賢くて、そこそこ雑用をこなせるプレイヤー」が何体も動いているほうが、全体としてはよほど強い。
そう考えると、GLM-5 のようなフロンティア志向のモデルは、少なくとも「日常の仕事を回す主役」ではない。今回のテストで見えた“整形のうまさ”も、実務の現場では、軽量モデル+ツールの組み合わせで十分に代替できる範囲に収まっている。

では、フロンティアモデルは不要なのか。
もちろん、そんな話にはならない。彼らが狙っているのは、もっと別の領域だ。より長い文脈を一度に抱え、より複雑な知識を統合し、より抽象度の高いタスクをまとめて扱う。エージェンティックな分業では分割しきれない塊を、そのまま飲み込める存在であること。そこに価値がある。
問題は、その価値が「日常の実務」からは少し遠いところにある、という点だ。
だからこそ、フロンティアモデルの評価は、どうしても派手なデモやベンチマークに寄りがちになる。一方で、実際に触ってみると、今回のように「地味に整っている」という感想に落ち着くことも多い。このズレが、フロンティアモデルの居場所を分かりにくくしている。
要するに、いまは過渡期なのだと思う。
軽量で仕事を卒なく回すプレイヤーたちが前線に並び、その後ろで、フロンティア寄りの巨大モデルが「別の価値」を追い続けている。GLM-5 は、まさにその後者側に立つモデルであって、実務の即戦力というよりは、「もう一段先」を見据えた存在だ。
第6章:それでもフロンティアモデルは進化し続ける
エージェンティック AI の文脈で見ると、フロンティア寄りの巨大モデルは、どうしても「重くて扱いにくい存在」に見えてしまう。軽量モデルとツールの組み合わせで回る仕事が増えれば増えるほど、その傾向は強まる。実際、日常業務の多くは、そちらのほうが合理的だ。
それでも、フロンティアモデルの開発が止まる気配はない。
それは、彼らが目指している価値の置きどころが、そもそも違うからだ。
フロンティアモデルが追っているのは、「分業して回す仕事」ではなく、「分業しきれない塊」をそのまま扱う能力だ。長大な文脈を一気に抱え込み、複数の領域にまたがる情報を同時に参照し、途中で細かく分解せずに一つの答えへまとめる。そういう種類のタスクは、ツール呼び出しとワークフローの組み合わせでは、どうしても設計コストが跳ね上がるか、運用が不安定になる。
GLM-5 のようなモデルは、その「設計コストをモデル側に押し込む」方向の進化をしているように見える。総パラメータ数を大きくし、MoE で必要な部分だけをアクティブにし、長いコンテキストを前提にする。これらはすべて、「一度に抱えられる問題のサイズ」を拡張するための設計だ。
今回の軽いテストから、その真価が測れるわけではない。
mxGraph の図解や、簡単な Web ページ生成は、せいぜい「整形の癖」を見る程度の話に過ぎない。それでも、そこで見えた「破綻しないまとめ方」や「欲張らない落としどころ」は、モデルが狙っている方向性と無関係ではないだろう。巨大であるがゆえに、暴れず、雑にならず、一定の品質に収める。そのための設計が、裏で効いている可能性はある。
そして、もうひとつ重要なのは、GLM-5 が OSS という形でこの領域に踏み込んできた という点だ。
これまでもフロンティア級のモデルは存在していたが、多くはクローズドな環境で提供され、使い方も評価方法も、プラットフォーム側に強く依存していた。GLM-5 は、そのスケールと設計思想を、少なくとも「触れる形」で外に出してきた。これは、「日常業務に便利な道具」というより、「研究と実験のための足場」に近い価値を持つ。
つまり、フロンティアモデルの進化は、実務の効率化とは別の軸で続いている。
軽量モデルが前線を支え、巨大モデルが後方で限界を押し広げる。その二層構造は、しばらく続くはずだし、GLM-5 はその後者側の代表例として、かなり分かりやすい位置に立っている。
第7章:GLM-5は“実務の主役”ではないが、“別の価値”を示している
ここまで、かなり地味なテストを通して GLM-5 の“手触り”を見てきた。
フロンティア性能を誇示するような派手なベンチマークでもなければ、難問を解かせて驚かせるような話でもない。OSI の図解や、簡単な Web ページ生成といった、どうでもいいくらい平凡な仕事をさせて、その出てきた形を眺めただけだ。
それでも、いくつか分かったことはある。
GLM-5 は、変に尖らず、破綻せず、「それなりにちゃんとした形」にまとめてくる。説明文の粒度、整形の癖、欲張らない落としどころ。どれも革命的ではないが、アウトプットをそのまま扱う側から見ると、確かに一段階の余裕を感じさせる。
一方で、これがそのまま「実務の主役になるか」と言われると、答えはおそらく違う。
いまの現場で求められているのは、軽くて速くて安定したモデルを、ツールやワークフローと組み合わせて回すことだ。エージェンティック AI の流れが示す通り、仕事は分解され、役割は分担され、巨大モデルひとつに全部を任せる必然性は、むしろ減っている。
その意味で、GLM-5 の立ち位置は少し宙ぶらりんだ。
便利な軽量ワーカーでもないし、日常業務を一気に変える魔法の道具でもない。今回のテストで見えた範囲でも、その距離感ははっきりしている。
それでも、このモデルには別の価値がある。
それは、「フロンティア寄りの領域に、OSS という形で誰でも手を伸ばせる足場を用意したこと」だ。巨大な文脈を一度に扱う設計、分業しきれない塊をまとめて処理する思想。その方向性自体は、実務の即効性とは別の軸で、確実に意味を持っている。
軽量モデルが前線を支え、フロンティアモデルが後方で限界を押し広げる。
その二層構造の中で、GLM-5 は後者側の代表例として、分かりやすい場所に立っている。今回の軽いテストは、その「性格」を覗き見ただけに過ぎないが、それでも、単なる話題作りではない進化の方向は感じ取れる。
実務の主役ではない。
だが、別の価値を追い続ける存在として、GLM-5 はきちんと意味のある場所にいる。
少なくとも、「フロンティアを OSS で触れる時代」に入った、という事実を象徴するモデルのひとつであることは、間違いなさそうだ。



