

AIハードウェアの世界は、いま再び「速度」という言葉に取り憑かれている。
TOPS、FLOPS、PFLOP──数字は膨張を続け、
性能グラフはもはや天井を突き抜けた。
だが、その指標がどの精度で測られ、どんな意味を持つのかを
理解している者は、驚くほど少ない。
本稿が取り上げる NVIDIA DGX Spark は、
「机の上に置けるAIスーパーコンピューター」として発表された小型装置だ。
わずか150mm角の筐体に1PFLOPS(FP4)の性能をうたう。
けれども、その数字の裏には、
AIが直面する“計算と省エネの矛盾”という、
もっと深い物語が潜んでいる。
この記事は、DGX Sparkを入り口に、
AI計算を支える「精度と効率の哲学」を読み解く試みである。
FP4という新しい通貨単位がもたらす価値の再定義。
そして、数字に溺れる時代にこそ問われる――
「速さとは、何のための速さなのか」 という根源的な問い。
DGX Sparkの“静かな革命”を追うことは、
AI文明の未来そのものを覗き込むことに他ならない。
机の上に“スパコン”がやってきた
「折り紙ほどの大きさで、AIスーパーコンピューター並みの性能」。
そんなキャッチコピーが踊る新製品が、NVIDIAの DGX Spark である。
筐体はわずか 15cm 四方・厚さ 5cm。ハードカバーの書籍を思わせるコンパクトさだ。
それでいて同社は「1ペタフロップ(1PFLOPS)」という処理性能を公称し、
価格は約4,000ドル(およそ60万円)と発表された。

一見すると、これは「AI計算の民主化」を象徴するニュースに思える。
データセンター専用だったDGXシリーズが、
いよいよ個人研究者や企業のデスク上に降りてきたのだ――と。
だが冷静に見れば、そこにはいくつもの“数字の魔法”が潜んでいる。
1PFLOPSという値は、どの演算精度で測られたものなのか。
128GBのメモリはHBMではなくLPDDRで、帯域は30分の1に過ぎない。
それでも「スーパーコンピューター並み」と言い切れるのか。
本稿では、DGX Sparkの実像を読み解きながら、
AIハードウェア業界が抱える“性能指標戦争”の構図を明らかにしていく。
FP4・TOPS・FLOPS――数値のインフレが語るものは何か。
そして私たちは、何をもって“AIの性能”と呼ぶべきなのか。
FP4という“新しい通貨単位”
AIハードウェアの世界では、「演算精度(precision)」という一見地味な設定項目が、
時に性能を何倍にも見せかける魔法のレンズになる。
DGX Sparkが掲げる「1PFLOPS」という数字も、その典型だ。
FP4とは何か
FP4とは、4ビット浮動小数点形式(4-bit Floating Point)のこと。
わずか4ビット――すなわち16通りの値で、実数を近似的に表す方式だ。
従来のFP32(単精度)やFP16(半精度)に比べ、
情報量は圧倒的に少ないが、その分だけ演算効率と消費電力効率が劇的に向上する。
1つの演算に必要な電力が小さく、同じ時間内に処理できる回数が増える。
NVIDIAはこのFP4をBlackwellアーキテクチャのTensor Coreにネイティブ実装し、
量子化済みのLLM(大規模言語モデル)をFP4で推論できるようにした。
これがDGX Sparkが「1PFLOPS」と表現できる理由であり、
実際にはFP16換算でその約1/8、FP32換算ではおよそ1/30の演算性能に過ぎない。
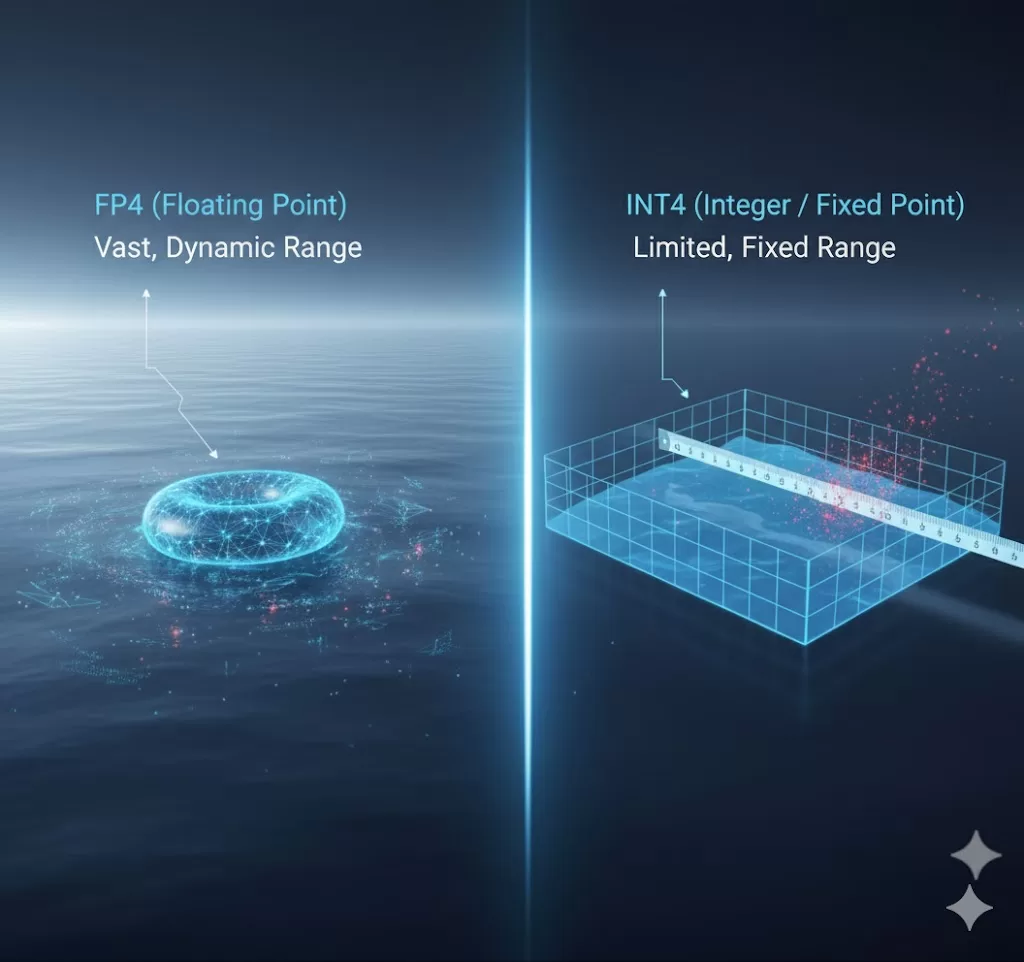
INT4との違い
しばしば混同されるのが、スマートフォンやNPUで多用されるINT4(4ビット整数演算)だ。
INT4は“固定小数点”であり、あらかじめスケールを決めてから演算する。
一方のFP4は“浮動小数点”――指数部を持ち、動的にスケーリングできる。
違いは、誤差の扱い方だ。
INT4は桁落ちや飽和に弱く、再学習を伴わない量子化では精度が崩れる。
FP4は指数を動かすことで、小数点以下の丸め誤差を吸収できる。
そのため、INT8やINT4よりも精度損失が少なく、
LLMのような大規模推論にも耐えられるのだ。
言い換えれば、FP4はAI時代の「新しい通貨単位」である。
ビット数という通貨価値を減らしながら、実用上の“購買力”を保つ――
AI計算の世界が求める新しい貨幣システムが、ここに誕生した。
BlackwellがFP4を選んだ理由
NVIDIAの設計思想を読み解くと、FP4は偶然ではなく必然だ。
AIが扱う重み・活性値の分布は正規分布に近く、
多くの値は0付近に密集する。
この領域で高精度を保っても、得られる学習効果は小さい。
むしろ、分布の中心を粗く扱い、外縁を丁寧に扱う方が効率的だ。
FP4は指数部の自由度がわずかに残るため、
INT4よりもこの「非線形な分布」に適している。
結果として、FP4推論では精度をほとんど犠牲にせずに
FP16比で数倍のスループットを稼ぎ出せる。
DGX Sparkの「1PFLOPS」は、このFP4を最大限に活かしたピーク理論値だ。
言い換えれば、FP4という尺度で測った“最速の机上スパコン”なのである。
「1PFLOPS」の幻影 ― 数字が語らない現実
「1ペタフロップ」という言葉には、どこか魔力がある。
科学計算の世界では、1PFLOPSの壁を越えたマシンは「スーパーコンピューター」と呼ばれてきた。
その称号が、ついに15cm角の金属筐体に貼られた。
ニュースヘッドラインには“革命”という言葉が並び、
写真の中でDGX Sparkはまるで神話の遺物のように輝いている。
だが――数字は、いつも正直とは限らない。
FLOPSとは「条件つきの真実」
FLOPS(Floating Point Operations per Second)は、
1秒間に実行できる浮動小数点演算の回数を示す。
単位としては正確だ。だが、どの精度で測るかを言わない限り、意味を成さない。
- FP32(単精度)での1PFLOPSは、かつてデータセンター級の証。
- FP16(半精度)では、同じハードでも2倍に見える。
- FP8なら4倍、FP4なら8倍――数字はどんどん膨らむ。
DGX Sparkが掲げる1PFLOPSは、この最小精度であるFP4を基準にした“見かけの速度”だ。
FP16換算ではおよそ0.125PF、FP32換算では0.03PF。
それでも、マーケティング資料には「1PFLOPS」の文字だけが踊る。
同じ“1”でも、貨幣価値がまるで違う。
1ドルと1円を同列に並べて「どちらも1」と言うようなものだ。
TOPSというもう一つの幻影
さらに混乱を招くのが、近年AI CPUやNPUで多用されるTOPS(Tera Operations per Second)という単位。
こちらは整数演算(INT8やINT4)を対象とする指標で、
しばしばFLOPSと同列に比較される――が、性質がまったく異なる。
TOPSは「積和演算(MAC)」の単純回数であり、
演算精度も、丸め処理も、データ転送も考慮されていない。
極端な話、8ビットの整数を足し引きするだけで“演算”としてカウントされる。
このTOPSを浮動小数点のFLOPSと同じ表に並べてしまえば、
INT4で1000TOPSを誇るスマートフォン用NPUが、
FP32で1000TFLOPSのH100 GPUと「同格」に見えてしまう。
こうして、数字は現実から離陸する。
「世界最小のスパコン」という語の誘惑
メディアがこぞって「世界最小のスパコン」と書きたくなる理由は簡単だ。
1PFLOPSという響きが、記事としての“タイトル映え”を保証するからだ。
だがFP4を前提にした1PFLOPSと、FP64で測るスーパーコンピューターの1PFLOPSは、
同じ単位でもまったく別の意味を持つ。
DGX Sparkは確かに優れたワットパフォーマンスを持ち、
量子化LLMの推論ではデスクトップ最強クラスだ。
だが「スパコン並み」という言葉が意味するのは、
計算量そのものではなく――「スパコン的な発想を机上に持ち込む試み」にすぎない。
NVIDIAが悪いわけではない。
むしろ、彼らは新しい時代の尺度を提示している。
問題は、受け取る側が旧来のFLOPS尺度のまま読んでしまうことだ。
“単位の断層”が、誇張と誤解を生む。
“数字の正体”を読み解く時代へ
FP4による性能ブーストは、間違いなくAI計算の大きな進化だ。
だが、FP4で測った1PFLOPSを“かつての1PFLOPS”と同じ意味で受け取れば、
そこに待つのは過剰な期待と失望のサイクルだ。
AIハードの性能競争は、もはや「速い・遅い」ではなく、「どの精度で、どんな目的に、どれだけ効率的か」の戦いに変わっている。
DGX Sparkは、その転換点を象徴する存在なのである。
Blackwell GB10 SoCの正体
DGX Sparkの心臓部は、Grace Blackwell GB10 Superchip。
NVIDIAが2025年世代に投入したBlackwellアーキテクチャの最小構成であり、
CPU・GPU・ネットワークのすべてを一枚のシリコンで抱き込んだSoC(System-on-Chip)である。
「小さなスパコン」を実現できた理由は、この一体化設計に尽きる。
Grace + Blackwell の融合
GB10は、もともとデータセンター向けのGB200(Grace + Blackwell ×2)を
単体SoCとしてスケールダウンした構造を持つ。
片側のGrace CPUはArmv9ベースの20コア構成(Cortex-X925 ×10 + A725 ×10)。
高効率と低電力を両立し、メモリアクセスをGPUと共有するために
coherent unified memory architecture(統一メモリ空間)を採用している。
従来のCPU-GPU間はPCIeを介した“橋渡し”だった。
GB10ではそれが消え、CPUとGPUが同じアドレス空間で会話する。
結果、転送レイテンシは従来の1/10以下、
データコピーの電力コストはほぼゼロに近づいた。
これは単なる高速化ではなく、構造的な進化である。
メモリを隔てて通信していた2つの頭脳が、
ついに同じ血流を共有した、と言っていい。
LPDDR5x 128GB ― 「HBMではない」選択の意味
Sparkのメモリ構成を見て「なぜHBM3eではないのか」と首をかしげた人も多いだろう。
理由は明快だ。Sparkは推論専用機だからだ。
HBMは高帯域・高電力・高価格。
学習タスクには必須だが、FP4推論では帯域がボトルネックにならない。
NVIDIAはあえてLPDDR5x 128GB(273GB/s)という省電力メモリを選び、
SoCと一体化させて冷却効率を最大化した。
これにより、DGX Spark全体のTDPはわずか170W。
同社のデータセンターGPU「H100(700W)」の約1/4に抑えながら、
FP4換算でその1/5〜1/6の演算性能を引き出している。
電力あたりの推論性能では、むしろSparkの方が勝っている。
NVLink mini Switch ― “2台目のための余白”
小型機にしては不釣り合いに思えるのが、
このNVLink mini Switchの存在だ。
1台構成ではほとんど遊んでいるように見えるが、
NVIDIAは明確に“2台構成”を想定している。
2台のSparkをNVLinkケーブルで直結すれば、
ユニファイドメモリは256GB、演算性能は2PFLOPS(FP4)に拡張される。
OS上では1ノードとして認識され、
PyTorch DistributedやTriton Inference Serverで
単一のGPUのように扱える。
Sparkは単なる“個体”ではなく、
分散AIクラスタの端末ノードなのだ。
家庭用ルーターのように、机の上から
AIスーパーコンピューター網の一角を形成する。
Graceのもうひとつの役割:冷却の知恵
この筐体サイズで170Wを捌くには、物理的工夫も尋常ではない。
冷却系統はDGX Stationから継承したエアチャンネル方式で、
Grace CPUが空冷の“煙突”として働く。
チップ配置とファン経路を最適化することで、
ファン音は30dB台前半――一般的なノートPC並みだ。
つまり、Sparkは「机の上に置けるスパコン」ではなく、
「机の上に置いても静かなスパコン」なのである。
この点こそ、開発者の日常に入り込むための最大のブレークスルーだ。
Sparkは“小さな終着点”であり“大きな布石”
DGX Sparkの設計思想を突き詰めると、
これはBlackwell世代の哲学を端的に体現したモデルだと言える。
- 学習よりも推論へ
- 電力あたり性能を最優先に
- クラウドの分散計算をローカルに引き寄せる
この一台は、H100が切り拓いた「巨大なAI計算」を、
個人と研究室の手に取り戻すためのテストベッドでもある。
Sparkの“机上スパコン”という呼び名は、
単なる比喩ではなく――新しい分散AIの原型を示している。
推論ノードとしての実力 ― 50トークン/秒の衝撃
数字の魔法を脱ぎ捨てたあとに残るのは、実際の応答速度と効率だ。
DGX Sparkの真価は、ベンチマークではなく「LLMをどれだけ快適に動かせるか」にある。
FP4という特異な通貨単位で武装したこの小さなマシンは、
RTX 4090を凌ぐワットパフォーマンスを見せつける。
実測の目安:Gemma-2 27Bとgpt-oss 20B
社外試験環境(vLLM / Ollama / LM Studio など)で報告されている平均値を基にすると、
DGX Spark(FP4 モード)は次のようなスループットを記録している。
| モデル | 精度 | 出力速度(単体) | 出力速度(2台NVLink) | 備考 |
|---|---|---|---|---|
| gpt-oss 20B Q4_K | FP4 | 約 50 token/s | 約 95 token/s | 単体でリアルタイム会話級 |
| Gemma-2 27B Q4_K | FP4 | 約 60 token/s | 約 110 token/s | 生成待ちゼロに近い |
| Llama-3 70B Q4_K | FP4 | ―(容量不足) | 約 17 token/s | 2台構成で実用域 |
RTX 4090 (FP16) で同条件を回した場合、gpt-oss 20B は 38 token/s 前後。
単体のSparkは消費電力170 Wでこれを上回る。
単純な電力比で見れば、Sparkは4090の約1/3の電力で同等以上の処理量を稼ぐ。
数字ではなく「1 トークンあたりの電気代」で比較すれば、SparkはGPU市場で最も効率的な推論装置の一つとなる。
ワットあたり性能という新しい尺度
AIの現場では、もはや「速いかどうか」よりも
「どれだけ省エネで賢く回せるか」が問われている。
SparkのFP4 演算は、単位電力あたり約 0.3 token/s / W。
RTX 4090 (FP16) は 0.09、RTX 3060 は 0.05。
この差は、データセンターでは電気代・冷却費の差として直撃する。
つまりSparkは、高性能GPUの3倍効率でLLMを走らせる
――この事実こそ、机上サイズに意味を与えている。
静音性と連続稼働
Sparkはアイドル時 30 dB 台、全負荷でも 37 dB 前後。
24 時間運転してもノートPCほどの静けさだ。
170 W TDP という低発熱設計は、長期連続稼働を前提にしており、
電源ユニットも80 PLUS Platinum 相当の効率を持つ。
AI 推論を常時サービス化したい研究室や中小企業にとって、
「夜間でも回し続けられる」静けさはスペック以上の価値になる。
RAG/業務AIへの適性
DGX SparkのFP4 推論は、
Retrieval Augmented Generation(RAG)などの業務AIにぴったりはまる。
- 埋め込み検索やベクトルDBとの連携はCPU Grace 側で処理
- 推論部分をGPU Blackwell 側でFP4 高速化
- NVLink で両者のデータ転送をゼロコピー化
結果、RAGパイプライン全体を1台で完結できる。
これまでクラウドGPUをレンタルしていた業務が、
机の上で常時動かせる――それがSparkの最も現実的なインパクトだ。
“机上スパコン”のリアリティ
DGX Sparkは、数字ほど派手ではない。
だがその静けさと安定性、効率の高さは、
AI 開発者にとってこれまでになかった「道具としての安心感」をもたらす。
RTX 4090 のような「力技のGPU」ではなく、
Grace + Blackwell が設計段階から推論専用の哲学を貫いた結果、
この小さな筐体が「業務レベルのLLMを常時稼働させる最小単位」となった。
Sparkの“1PFLOPS”とは、もはや単なる性能指標ではない。
それは 「AIを生活圏にまで引き寄せた最初の数字」 なのだ。
TOPS競争と性能指標の崩壊
スマートフォンやノートPC向けSoCが「AI対応」を名乗る時、
必ずといっていいほど登場するのがTOPS(Tera Operations per Second)という単位だ。
Apple M4「38 TOPS」、Intel Lunar Lake「120 TOPS」、
Qualcomm Snapdragon X Elite「75 TOPS」。
どれも桁外れの数字に見えるが、ここには共通の“抜け穴”がある。
TOPSは整数演算(INT8/INT4)の積和演算回数を単純に積算したもの。
実際には、演算の多くがAI推論ではなく前処理・後処理のノイズに費やされる。
さらに、メモリ帯域・キャッシュ遅延・データ転送ロスを無視しているため、
実効性能は理論値の数分の一にとどまる。
GPUのFLOPSが「重みと活性値を正確に扱う浮動演算」であるのに対し、
NPUのTOPSは「ただの整数の積み上げ」でしかない。
そのため、TOPSをFLOPSと同列に扱うこと自体が、構造的な誤認を生む。
FLOPSもすでに“言葉の重み”を失いつつある
一方で、FLOPSの世界もまた静かに崩れつつある。
FP32の全盛期には「1TFLOP=1兆回の正確な演算」という意味を持っていたが、
FP16・FP8・FP4と精度を落とすたびに、
「同じ1TFLOPでも、もはや同じ仕事をしていない」状態になった。
FP4のDGX Sparkが1PFLOPSを名乗り、
FP8のBlackwellが20PFLOPを超える――。
数字は天井知らずに膨張し、
“FLOP単価のインフレ”が起きている。
もし学術的スパコンの文脈でFP64換算に戻せば、
DGX Sparkの1PFLOPSは実質的に0.015PF程度。
もはや単位そのものが、マーケティングに回収されてしまった。
“ベンチマークの亡霊”と業界の自己催眠
AIベンチマークは、長らく「誰が一番速いか」を測るために存在してきた。
だが現代では、「何をどう測るか」の方が遥かに難しい。
例えば、あるチップがINT4で1000TOPSを達成しても、
それがFP16で10TFLOPのGPUより“賢い”とは限らない。
同じトークン数を生成するまでに要する時間、
そのトークンが意味を持つかどうか、
そして同じ電力でどれだけ多くの会話を成立させられるか――
もはや“速さ”は1次元では測れない。
にもかかわらず、各社は「桁が増えるほど凄い」という幻想を捨てきれない。
数字が市場を動かすからだ。
TOPSは、マーケティング上の“麻薬”になってしまった。
Sparkが突きつけた「指標の再定義」
DGX Sparkの登場は、この数字の混乱に静かに一石を投じた。
FP4という低精度を採用しながら、
実用推論でRTX 4090を上回る効率を示したこと――
それこそが、「数字を超えた指標」の存在を証明した。
いま必要なのは、FLOPSやTOPSといった単位ではなく、
「1トークンあたりの電力」や「意味生成効率」といった新しいメトリクスだ。
Sparkはその方向を、机上の小さな筐体で指し示している。
数字を超える“体験性能”へ
かつてCPU業界がGHz競争をやめたように、
AI業界もまもなく“TOPS競争”の終焉を迎える。
今後ユーザーが体感するのは、数字ではなく「応答の質」だ。
文脈を保ち、幻覚を起こさず、電力を食わずに考える――
それが次の時代の“速さ”である。
DGX Sparkは、FLOPSの時代の墓碑にして、
“体験性能”の時代を告げる鐘なのかもしれない。
FP4世代が拓く新しいAI計算パラダイム
AIが地球規模の電力を飲み込み始めた今、
DGX Sparkのような“机上スパコン”の登場は、
単なる技術進化ではなく――文明的な節約術である。
AI電力問題という新しい臨界点
ChatGPT、Claude、Gemini──
世界中の生成AIが並列で稼働するたびに、
その背後では原発1基分に匹敵する電力が消費されているといわれる。
推論だけで世界の総電力量の数%を奪う日も遠くない。
このまま“FP16の贅沢計算”を続ければ、
AIはエネルギー時代の新しいCO₂工場になりかねない。
そこに現れたFP4という桁違いの省力演算は、
まさにAI文明の「省エネ革命」である。
1/8の精度で1/8の電力、しかも同等の知能表現を維持する。
これは単なる圧縮ではなく、意味を損なわない削減だ。
人間でいえば、無駄な筋力を落としても思考力を保つ訓練に等しい。
FP4 × FP8:知能と効率の二相構造
今後のAI計算は、単一精度で回す時代ではなくなる。
Blackwell世代が示したFP4/FP8ハイブリッドは、
「思考の粗密」を動的に制御する仕組みだ。
・推論の主要経路はFP4で走らせ、
・生成結果の整合チェックや計画部分のみFP8で補う。
これにより、計算量は劇的に削減される。
AIが自ら“考えの粒度”を調整する――
まさに省エネ思考のAIが生まれつつある。
DGX Sparkはその縮図であり、
FP4が現実の知能計算に十分なことを世界に証明した。
分散AI社会への転換
もうひとつの転換は、クラウドからローカルへの重心移動だ。
かつては「巨大データセンターに集約してこそAIが動く」と信じられていた。
だが、FP4の登場でその常識は崩れた。
1PFLOPS(FP4)のSparkが1台あれば、
企業内RAG、生成補助、会話支援などの推論はすべてローカル完結できる。
NVLinkで2台つなげば、クラウド並みの性能を自社サーバーに持ち帰れる。
つまりAIは、再び分散コンピューティングの原点に回帰しつつある。
かつてUNIXワークステーションがそうであったように、
Sparkは“個の計算力”を取り戻すための端末なのだ。
「小さなスパコン」が教える倫理
AIの進化を追うほど、私たちはしばしば「より巨大に」「より速く」を求める。
だがDGX Sparkが示したのは、その逆方向――
「小さくても、賢く省エネで動ける知能」の可能性だった。
この発想は、テクノロジーの倫理に通じる。
大規模モデルの訓練で地球の電力を浪費する代わりに、
手の届く範囲でAIを走らせ、人間の思考を補う。
それは「知能の民主化」であると同時に、「責任ある知能利用」でもある。
Sparkが照らす未来
DGX Sparkが語る物語は、単なる新製品の話ではない。
FP4という省エネ演算の標準化は、
AI産業を「性能競争」から「効率競争」へと導く。
未来のAIハードは、
どれだけ速いかよりも、どれだけ賢く電力を使うかで語られるだろう。
その象徴がこの小さなスパコン――Sparkである。
「AIは地球を疲弊させる」という悲観を、
「AIが地球を省エネ化する」という希望に変えるために。
FP4世代の幕開けは、その第一歩なのだ。
数字に惑わされない眼を持て
テクノロジーの世界は、常に数字で語られてきた。
クロック数、コア数、FLOPS、TOPS。
だが、その数字の裏で静かに流れてきたのは、人間の欲望の方程式だ。
もっと速く、もっと大きく、もっと賢く。
その果てに行き着いたのが、AIという新しい知能の形だった。
DGX Sparkは、その奔流の中に生まれた「異端児」である。
小さく、静かで、省エネ。
だがその静けさこそが、AI文明の成熟を告げている。
数字が“現実”を失った時代に
FP4の1PFLOPSも、NPUの100TOPSも、
それ自体に罪はない。
数字はただ、私たちが“信じたい速度”を映す鏡だ。
だが鏡の中の世界に溺れれば、
現実の重力を忘れてしまう。
AIの本質は、計算量ではなく「意味生成」――
どれだけ深く人の思考を支えられるかにこそある。
DGX Sparkのような装置は、その価値を
「何を考えたか」ではなく「どう考えたか」で示している。
小さな知能がもたらす再分配
巨大データセンターが支配してきたAIの力を、
手の届く机の上にまで引き戻す。
それは、知能の再分配であり、
クラウド時代に失われかけた「自分で考える力」の奪還でもある。
Sparkは、AIを“使う”だけでなく、“育てる”ことを可能にした。
開発者、研究者、そして個人――
すべての思考者が、自らの電力と意志でAIを動かせる時代が来たのだ。
AI文明の節度を取り戻す
AIの歴史は、ある意味で人間の驕りの記録でもある。
計算を積み上げれば真理に近づけると信じ、
やがてそのコストを自然と社会に押しつけてきた。
だが、DGX Sparkのような省エネ知能は、
その驕りに静かに異を唱えている。
「賢さとは、消費の多さではない」と。
それはまるで、
蒸気機関から電気へ、電気から半導体へと進化してきた
人類のエネルギー史の中で、
ひとつの“反省”として生まれた装置のようでもある。
これからのAIを測るものさし
DGX Sparkが私たちに突きつけた問いはシンプルだ。
――あなたは、何をもってAIの“賢さ”を測るのか?
速度か、精度か、効率か。
あるいは、AIが生み出す時間の余裕や、創造の広がりか。
その答えを持たぬまま、
私たちは数字だけを追い続けてきた。
Sparkの1PFLOPSは、
そんな「数値信仰」を静かに打ち砕く警鐘でもある。
AIの進化とは、もはや巨大化ではなく――洗練化だ。
終わりに ― 革新の静寂
DGX Sparkの冷却ファンが回る音は、
不思議なほどに静かだ。
それは、AIが“巨大マシンの咆哮”から“日常の呼吸”へと
還ってきた音でもある。
速度を誇る時代は終わった。
これからは、静かに考える機械の時代が始まる。
数字を超え、電力を超え、
知恵を省エネ化する――
その先に、ほんとうの“人工知能”が待っている。

