

はじめに ─ AIが絵を描く時代の始まり
いま私たちは、文章を入力するだけで画像を生成できる時代に生きている。
風景、イラスト、写真風の人物。わずか数秒から数十秒で、AIはそれらしい画像を作り出す。
この体験はあまりにも自然になったため、まるで昔から存在していた技術のように感じられるかもしれない。
しかし実際には、画像生成AIの歴史は驚くほど短い。
AIが本格的に画像を生成し始めたのは、わずか十年ほど前のことだ。
その発展の過程は、巨大企業の研究所だけで進んだわけではない。
大学の研究室、スタートアップ、そして世界中の開発者たちが集まるGitHubコミュニティ。そうした場所で生まれた技術が連鎖し、現在の画像生成AIへとつながっている。
最初の転換点は、生成モデルというアイデアの登場だった。
その後、拡散モデルという新しい仕組みが登場し、画像生成は一気に現実的な技術になる。
さらにオープンソースとして公開されたモデルは、世界中の開発者によって改良され、UIツールや拡張機能が次々と生まれた。
画像生成AIは研究テーマから、誰でも使える創作ツールへと変わっていった。
そして現在、その流れは新しい世代のモデルへと受け継がれている。
本記事では、GANからStable Diffusion、そしてFLUXへと至る流れをたどりながら、画像生成AIを形作ってきた技術と人物を整理してみたい。
それは、わずか十年ほどの間に起きた、小さな技術革命の記録でもある。
第1章 GAN革命 ─ AIが画像を生成し始めた瞬間
2014年、モントリオール大学の研究室で、一つの論文が発表された。
著者は若い研究者、Ian Goodfellow。
その論文のタイトルは
Generative Adversarial Networks(GAN)。
日本語に訳すと「敵対的生成ネットワーク」となる。
名前だけ聞くと仰々しいが、仕組みは驚くほどシンプルだった。
AIを二つ用意し、それぞれに役割を与える。
一つは「生成器」。
ランダムなノイズから画像を作るAIだ。
もう一つは「判別器」。
その画像が本物か偽物かを見分けるAI。
この二つを対戦させる。
生成器は「本物に見える画像」を作ろうとし、
判別器は「偽物を見破ろう」とする。
この競争が繰り返されることで、生成器はだんだんと本物らしい画像を作れるようになっていく。
このアイデアは、AI研究者たちに大きな衝撃を与えた。
それまでの機械学習は、主に分類や予測を目的としていた。
猫か犬かを見分ける。
数字を認識する。
文章を分類する。
しかしGANは違った。
AIが「新しい画像を作る」ことができることを示したのだ。
その後、GANを使った研究は急速に広がっていく。
2010年代後半には、AIが生成した顔写真が話題になり、「この人物は実在しない」と紹介されるサイトも登場した。
AIが人間の顔を作る。
それは当時、多くの人にとって未来の技術のように見えた。
しかしGANには大きな問題もあった。
まず、学習が不安定だった。
生成器と判別器のバランスが崩れると、モデルは簡単に壊れてしまう。
さらに、生成された画像を思い通りに制御することも難しかった。
GANは優れた画像を生み出すことがあっても、それを「設計する」ことはできなかった。
つまりこの時代の画像生成AIは、まだ研究室の中の技術だった。
それでもGANは重要な役割を果たした。
AIが画像を生成できるという事実を、初めて現実のものとして示したからだ。
そして数年後、別のアプローチが登場する。
それが「拡散モデル」と呼ばれる技術だった。
この新しい仕組みが登場したことで、画像生成AIは研究テーマから実用ツールへと大きく前進することになる。
次の章では、その転換点となった技術、Stable Diffusionの登場を見ていこう。
第2章 拡散モデル革命 ─ Stable Diffusionの登場
GANの研究が盛り上がっていた2010年代後半、別の方向から画像生成を考える研究が進んでいた。
それが「拡散モデル」と呼ばれる手法だ。
拡散モデルの発想は、GANよりもずっと直感的だ。
まず画像に少しずつノイズを加えていく。
最終的には完全なノイズ画像になるまで、段階的に壊していく。
そしてAIに学習させるのは、その逆のプロセスだ。
ノイズだらけの画像から、少しずつノイズを取り除いていく。
その過程で、元の画像を復元していく。
つまりAIは、
ノイズから画像を作る方法
を学習する。
このアプローチは、GANよりも学習が安定していた。
また、画像の品質も大きく向上することが分かってきた。
そして2022年、この技術が大きな転換点を迎える。
ドイツの研究グループ
CompVis
のチームが、新しいモデルを公開した。
中心となった研究者は
Robin Rombach。
彼らが開発したモデルが
Stable Diffusion
である。
Stable Diffusionが革新的だった理由は、画像生成の仕組みそのものだけではない。
最大のポイントは、
一般的なGPUで動作する
という点だった。
それまでの高性能な画像生成モデルは、巨大な計算資源を必要としていた。
クラウドの大規模GPU環境がなければ動かせないものも多かった。
しかしStable Diffusionは違った。
モデルを「潜在空間」と呼ばれる圧縮された表現で処理することで、計算量を大幅に削減した。
これにより、一般的なPCのGPUでも画像生成が可能になった。
さらに重要だったのは、このモデルがオープンソースとして公開されたことだ。
研究論文だけではなく、実際に動くモデルとコードが公開された。
誰でもダウンロードし、自由に試すことができた。
この瞬間から、画像生成AIの世界は一気に広がる。
研究者だけでなく、プログラマー、アーティスト、そして好奇心旺盛なユーザーたちが、Stable Diffusionを使い始めた。
GitHubには次々とツールや拡張機能が登場し、コミュニティは急速に成長していく。
この出来事は、後になって振り返ると一つの転換点だったと言えるだろう。
画像生成AIはこの瞬間、研究室の技術から
世界中のユーザーが触れるツールへと変わったのだ。
そして次に起こるのは、さらに興味深い出来事だった。
研究者ではない開発者が、Stable Diffusionを誰でも使えるツールへと変えてしまう。
次の章では、その中心にあったプロジェクト
AUTOMATIC1111 WebUIと、GitHubコミュニティの爆発的な成長を見ていこう。
第3章 GitHubコミュニティの爆発 ─ AUTOMATIC1111という転換点
Stable Diffusionが公開された2022年、世界中の開発者たちがこのモデルを試し始めた。
しかし当時のStable Diffusionは、まだ研究コードに近いものだった。
Python環境を用意し、コマンドラインで実行し、設定ファイルを書き換える。
研究者やエンジニアならともかく、一般のユーザーには扱いにくい。
そこで登場したのが、あるGitHubプロジェクトだった。
AUTOMATIC1111 Stable Diffusion WebUI
作者はハンドルネーム
AUTOMATIC1111
で知られる開発者。
このツールの発想は非常にシンプルだった。
Stable Diffusionをブラウザから操作できるようにする。
ユーザーはWeb画面にプロンプトを書き、ボタンを押すだけで画像を生成できる。
設定もGUIで調整できる。
いまでは当たり前の体験だが、当時は大きな変化だった。
このWebUIが公開されると、Stable Diffusionの利用者は急速に増えていく。
研究者だけでなく、イラストレーター、デザイナー、ゲーム開発者、そして単なる好奇心から試すユーザーまで、多くの人が画像生成AIに触れるようになった。
さらに重要だったのは、このツール自体もオープンソースだったことだ。
世界中の開発者が拡張機能を作り始めた。
・LoRAによる軽量モデル追加
・アップスケーラー
・ポーズ指定
・インペイントやアウトペイント
Stable Diffusionの周辺には、巨大なツール群が生まれていく。
この頃から、画像生成AIの世界は「研究プロジェクト」ではなく、コミュニティ主導のエコシステムへと変わり始めた。
そしてこのコミュニティから、さらに重要な技術が生まれる。
それが ControlNet だった。
この技術は、画像生成AIに「構図」や「ポーズ」を理解させる方法を提供する。
つまりAIは、単にランダムに画像を作るのではなく、人間が設計した構造をもとに画像を生成できるようになった。
ここで画像生成AIはもう一段階進化する。
次の章では、この重要な技術を生み出した研究者
Lvmin Zhang
と、ControlNetがもたらした変化を見ていこう。
第4章 ControlNet ─ AIに構図を理解させる
2023年、画像生成AIのコミュニティに衝撃が走る。
新しい技術が公開された。
名前は
ControlNet
この技術を開発した研究者が
Lvmin Zhang。
ControlNetが解決したのは、Stable Diffusionの根本的な弱点だった。
それは「構図の制御」である。
Stable Diffusionは優れた画像を生成できるが、出力はある程度ランダムになる。
人物のポーズ、画面構成、視点などを細かく指定するのは難しかった。
そこでControlNetは、外部の情報を使って画像生成を制御する仕組みを導入した。
例えば、次のような入力をAIに与えることができる。
・人物の骨格(ポーズ)
・線画
・深度情報
・エッジ画像
・セグメンテーション
AIはこれらの情報を手がかりにして画像を生成する。
つまり、
構造を人間が決める。
AIはそれをもとに画像を作る。
という役割分担が可能になった。
この発明によって、画像生成AIは大きく変わる。
それまでの生成AIは、ある意味で「偶然の芸術」だった。
良い画像が出るかどうかは、プロンプトやランダム性に左右される。
しかしControlNetが登場したことで、
・ポーズ指定
・構図指定
・ラフスケッチから生成
といった、設計可能な画像生成が実現した。
これはイラスト制作やゲーム開発、デザインなどの分野で大きな意味を持った。
AIは単なる画像生成ツールではなく、
人間の創作を補助するツールへと変わったのだ。
さらに興味深いのは、この技術が企業ではなく、コミュニティの流れの中から生まれたという点である。
Stable Diffusionの公開によって、研究者と開発者が集まり、新しい技術が次々と生まれる環境ができていた。
ControlNetは、その象徴的な成果のひとつだった。
そしてLvmin Zhangは、もう一つ興味深いプロジェクトを作る。
それが Fooocus である。
Stable Diffusionの多くのUIは、数多くのパラメータを持つ。
サンプラー、ステップ数、CFGスケール、LoRA、VAE…。
それらは強力だが、初心者には分かりにくい。
Fooocusは、まったく逆の方向を選んだ。
設定を隠す。
ユーザーはプロンプトを書くだけでいい。
次の章では、この少し異端のツール
Fooocus
が、なぜ多くのユーザーに支持されたのかを見ていこう。
第5章 Fooocus ─ 設定を隠すという設計

Stable Diffusion系のツールの多くは、高度な設定をユーザーに公開している。
パラメータを細かく調整することで、画像の品質や生成スタイルを制御できるからだ。
しかし、すべてのユーザーがそれを望んでいるわけではない。
2023年に公開された
Fooocus
は、この点に大胆なアプローチを取った。
開発者は
Lvmin Zhang。
ControlNetの開発者でもある彼は、画像生成AIのUIについて一つの問いを立てた。
本当にこれだけの設定が必要なのか。
Fooocusの答えはシンプルだった。
ほとんどの設定を隠してしまう。
Fooocus の起動直後の画面UI

ユーザーは基本的に、プロンプトを書くだけでよい。
複雑なパラメータは内部で自動的に最適化される。
この設計思想は、Stable Diffusion系のツールの中ではかなり異色だった。
しかし実際に使ってみると、その合理性に気づく。
プロンプトを書き、ボタンを押す。
数秒後に画像が出る。
それだけだ。
さらにFooocusは、比較的軽量なモデルを組み合わせることで、古いGPUでも実用的な速度を実現している。
例えばHyper-SDのような蒸留モデルを使うと、生成ステップを大幅に減らすことができる。
従来の30ステップ前後の生成が、数ステップで収束する。
その結果、旧世代のGPUでも画像生成が可能になる。
GTX1060のような数年前のGPUでも、数十秒で画像を生成できる例は珍しくない。
現在のAI開発は、大規模GPUと巨大モデルを前提にした方向へ進んでいる。
しかしFooocusのアプローチは、それとは少し違う。
限られた計算資源でも使えるAI。
この設計思想は、Stable Diffusionが生み出したオープンなコミュニティ文化ともよく合っている。
そして画像生成AIの技術は、さらに次の世代へ進みつつある。
Stable Diffusionの研究者たちは、新しい企業を立ち上げ、次世代モデルの開発を進めている。
次の章では、その新しい流れを代表するモデル
FLUX.1
と、その開発元である
Black Forest Labs
について見ていこう。
第6章 FLUX ─ 次世代モデルの登場

2024年、画像生成AIの世界に新しい名前が登場する。
Black Forest Labs。
この企業は突然現れたわけではない。
実は、Stable Diffusionの研究に関わったメンバーが中心となって設立されたスタートアップである。
その彼らが発表したモデルが
FLUX.1。
FLUXは、Stable Diffusionの流れを受け継ぎながら、より高品質な画像生成を目指して設計された次世代モデルだ。
特に注目されたのは、画像のディテールと構図の安定性だった。
人物の手や指、細かな質感、複雑なシーンの描写など、従来のモデルが苦手としていた部分が大きく改善されている。
またFLUXは、テキストプロンプトへの理解度も高く、指示した内容をより正確に画像に反映する傾向がある。
その一方で、計算資源の要求はやや高くなった。
高品質な画像を生成するためには、比較的強力なGPUが必要になる場合も多い。
この点は、軽量モデルや高速生成を重視するツールとは対照的だ。
ここに、画像生成AIの現在の状況がよく表れている。
一方では、巨大モデルと計算資源を前提とした高品質路線。
もう一方では、限られたGPUでも動く軽量モデルや高速生成。
この二つの方向が並行して進んでいる。
FLUXは、Stable Diffusionの研究から始まった技術の流れが、再び新しい企業や研究へと枝分かれしていく過程を象徴している。
そしていま、生成AIの主戦場はさらに広がりつつある。
画像生成の技術は、動画生成、3D生成、リアルタイム生成など、新しい領域へ応用され始めている。
しかしその基盤を作ったのは、ここまで見てきた技術の積み重ねだった。
GANの発明、拡散モデルの登場、Stable Diffusionの公開、コミュニティによる改良、そして新しい世代のモデル。
これらの出来事が重なり、現在の画像生成AIの世界が形作られている。
次の章では、ここまでの流れを振り返りながら、画像生成AIの歴史がどのような意味を持つのかをまとめてみたい。
最終章 ─ 小さな革命としての画像生成AI
画像生成AIの歴史を振り返ると、一つの特徴が見えてくる。
それは、この分野の進歩が 比較的少数の研究者とコミュニティによって形作られてきたという点だ。
2014年、
Ian Goodfellow
が提案したGANは、AIが画像を生成できることを示した。
その後、拡散モデルという新しいアプローチが登場し、
CompVis
の研究チームは
Stable Diffusion
を公開した。
このモデルがオープンソースとして公開されたことで、状況は大きく変わる。
GitHubには数多くのツールや拡張が登場し、
AUTOMATIC1111 Stable Diffusion WebUI
のようなプロジェクトが、画像生成AIを誰でも使えるツールへと変えた。
さらに
Lvmin Zhang
による
ControlNet
は、画像生成を「設計できる」ものへと進化させた。
そして同じ流れの中から、
Fooocus
のような独自の思想を持つツールも生まれている。
研究室から始まった技術は、コミュニティを通じて急速に広がり、さらに新しい企業へとつながっていく。
その一例が
Black Forest Labs
による
FLUX.1
だ。
こうした流れを見ると、画像生成AIの歴史は単なる技術の進歩ではなく、オープンソースコミュニティが生み出した小さな革命だったとも言える。
現在、生成AIの主戦場は動画生成へと移りつつある。
しかし動画生成モデルの多くは、画像生成の技術を基盤としている。
つまり、いま起きている新しいAIの波もまた、この十年の積み重ねの上に成り立っている。
振り返ってみれば、画像生成AIの革命はそれほど昔の出来事ではない。
むしろ私たちは、まだその途中にいるのかもしれない。
そして次にどのような技術が生まれるのかは、研究室だけでなく、世界中の開発者たちの手に委ねられている。
付録:画像生成AIの歴史(主要転換点)
画像生成AIの進化は長い歴史を持つように見えるが、実際には2010年代後半から急速に進んだ分野である。
主な転換点を簡単に整理すると、次のようになる。
画像生成AIの主要年表
| 年 | 出来事 | 技術的意義 |
|---|---|---|
| 2014 | GAN提案(Ian Goodfellow) | AIが画像を生成できることを初めて示す |
| 2018 | StyleGAN登場 | 人物画像生成の品質が大きく向上 |
| 2021 | 拡散モデルの研究進展 | GANに代わる画像生成手法が確立 |
| 2022 | Stable Diffusion公開 | 一般GPUで動く画像生成AIが登場 |
| 2022 | AUTOMATIC1111 WebUI | 誰でも使える画像生成ツールが普及 |
| 2023 | ControlNet公開 | ポーズや構図を制御できる生成AI |
| 2023 | Fooocus公開 | 設定を隠すシンプルUIの登場 |
| 2024 | FLUX公開 | 次世代の高品質画像生成モデル |
画像生成AI 技術系統図
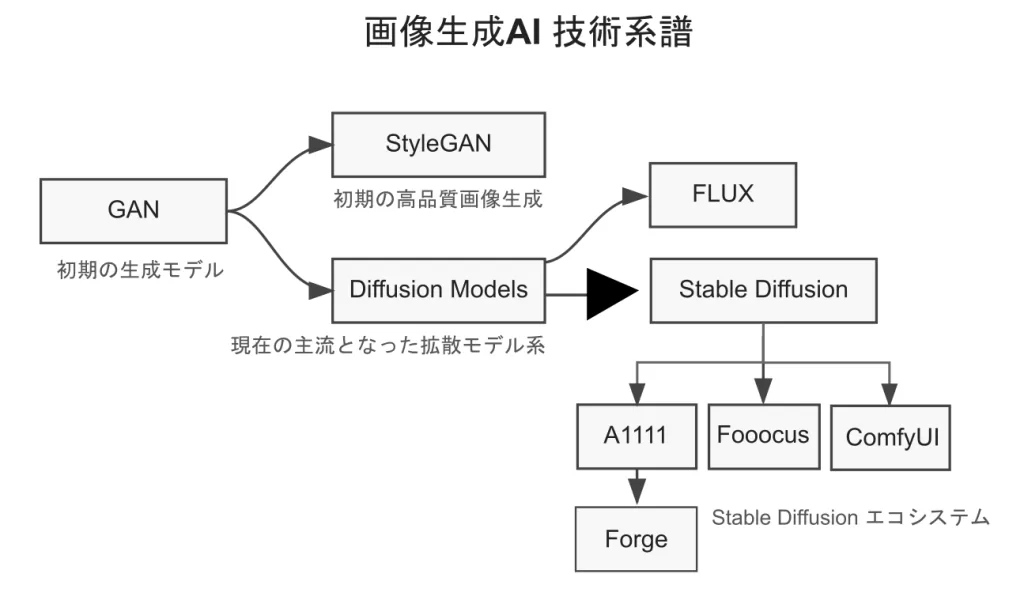
画像生成AIの発展は、研究者・オープンソースコミュニティ・スタートアップが連鎖的に関わりながら進んできた技術史でもある。




