── Qwen-3-VL に写真を食わせたら、想像以上に“見えていた話”
写真を整理していたときのことです。
あれ? この写真、名札写ってるじゃん…。
あ、こっちはナンバー映ってる…
人生で一度は必ず経験するやつ。
「この写真、そのまま SNS に出していいんだっけ?」問題です。
- 顔 → モザイク
- ナンバー → 塗りつぶし
- 名札 → トリミング
1枚ならまだいい。
1000 枚あったら 地獄。
■ Qwen Vision に画像を読み込ませた:まずは実験
“画像を理解する AI“── Vision LLM(Qwen-3-VL-4B)を使って、
「この画像からわかることを説明してください」
と聞いてみた。
軽い気持ちで。
そしたら 返ってきた答えが、完全に想像の外だった。
■ Qwen-3-VL は「画像を読む」:理解のレベルが違った
子供が公園で遊んでいる写真を見せたとき。

Qwen3-VL-4B の返答:
「子供が遊具の棒に手をついてバランスを取っている。
背後には緑色の恐竜型遊具が置かれている、奥には別の子どもが遊具の上に座っている」
恐竜の遊具?
別の子ども?
…見えてる。解釈してる。
別の写真。
胸元に名札がぶら下がっているビジネス写真。

画像引用:https://www.watanabedo-nametag-sign.jp/nafuda-tomegu.html
Qwen3-VL-4B の返答:
「名札。「有限会社渡辺堂」、「渡辺宗茂」
ブルーとブラウンのストライプ柄ネクタイ」
名札そのものだけじゃなく、
- 名札という概念
- 社名や氏名を認識できている
- 衣類の特徴を明確に理解できている
状況まで理解している。
ヤバい。
次の写真。
車のフロントのアップ。
”クォータロ” は御愛嬌w
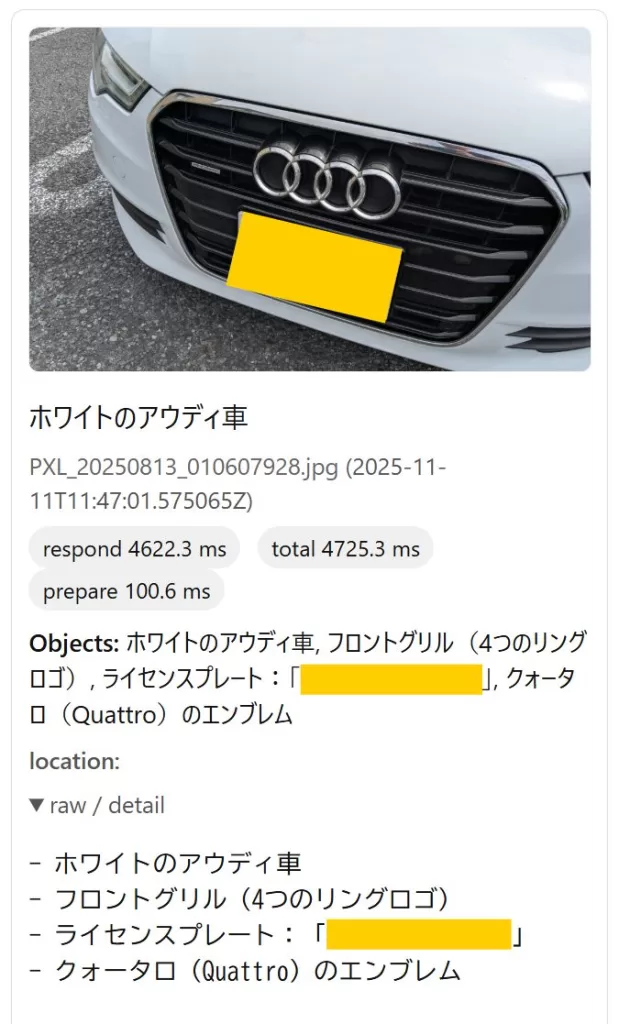
Qwen3-VL-4B の返答:
「ホワイトのアウディ車、
ライセンスプレート「〇〇-〇〇」が見えます。」
(※実ナンバーはこの記事では伏せています。ナンバーの認識は一字一句正解でした)
文字を読み取れるレベルで見ている。
僕はこの瞬間、震えた。
「あ、これ完全に個人を特定できる情報だ……」
人間が“うっかり”見逃す領域を、
AI は容赦なく拾いにいく。
■ Vision AI の本質:画像解析ではなく “意味理解”
AI は、
- 画像を “解析” しているのではなく
- 写真を “読解” している
AI は、写真の中身を理解してしまう。
ここが、OCR や古い画像認識との決定的な違い。
■ 画像 × 個人情報:AIは何をどこまで認識する?
写真を公開する際の最大の敵は、
「個人情報が写っていることに気づかない」
という“無意識”。
Vision AI はそこを撃ち抜く。
人間より先に気づく。
「これ、名札が写っていますよ」
「ナンバーが読めます」
「他の子どもが写っています」
AIは、未然に止めることができる。
■ AIは個人情報を認識できても、ぼかすことはできない
Vision AI ができるのは 判断。
- これは個人情報か?
- 公開しても安全か?
しかし、画像をぼかす処理はできない。
そこは別の技術(deface / OpenCV / YOLO)が必要。
しかし、最も重い作業は、もう AI がやってくれる。
「気づく」という一番面倒くさいところを
丸ごと自動化できる時代になった。
■ 結論:AIが見抜く時代に、人が決断する
- AIは写真に写っている内容を「理解」できる
- 名札やナンバーなど個人特定情報を認識できる
- 公開前に危険な画像だけ抽出できる未来が確実に来る
Vision AIは、写真を理解する。
僕の中で、パラダイムシフトが起きた。
もはや画像は“アップロード前にAIに相談する時代”。