

JSON を眺める作業から開放される。
Vision推論を “実務ツール” に変える。
■ はじめに
LM Studio で Vision 対応モデルを動かしたい──
そう思って検索しても「やってみた」「動かなかった」の感想ばかり。
Vision推論をローカルで実用する記事が、ほぼ存在しませんでした。
だから、作りました。
- LM Studio + Qwen3-VL-4B(Vision対応)
- Python スクリプトで画像をまとめて推論
- 画像+結果テキスト+処理時間を HTML で可視化
JSON のままだと読みづらいので、
画像ビューア付きの HTML(report.html)を自動生成する ようにしました。
JSON のログを見るのではなく、画像カードで結果を“読む” ためのツールです。
■ 何ができるのか(成果物)
以下のような HTML が自動で生成されます。
画像 + 推論結果 + 速度(ms)がカードで並ぶ
vision-tagger/
├── vision-tagger.py ← 実行するファイル
├── report_template.html
├── <report.html> ← ★自動生成(画像ビューア付き)
├── input/ ← 画像を入れるフォルダ
└── README.md
<report.html> 実際の表示例:
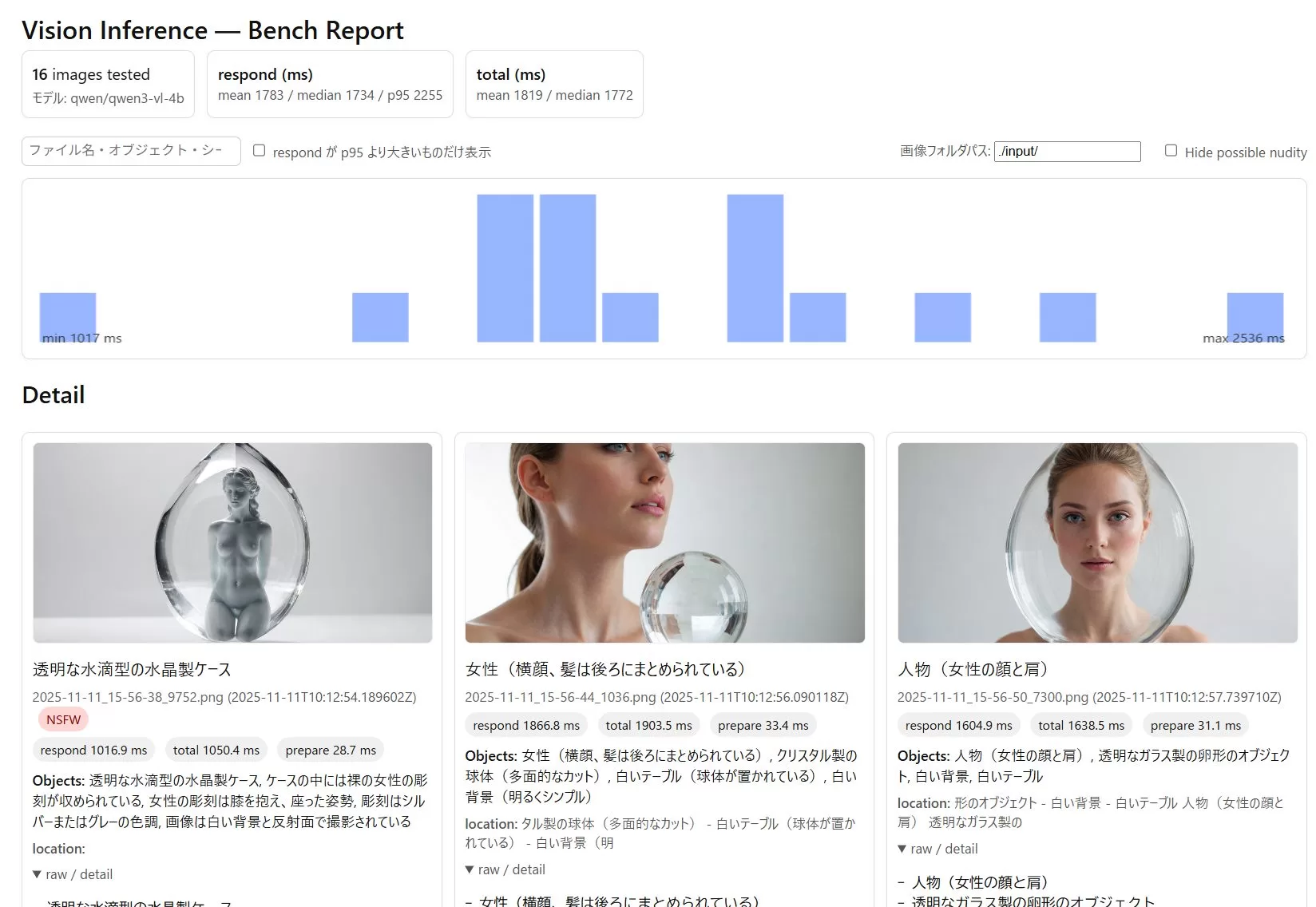
※テストに使用した画像は、Fooocus にて生成。1192x896pxで概ね1MB以下のサイズです。
■ Vision推論が“実務で使える”理由
Qwen3-VL は以下のように出力します:
- Objects: 透明な水晶製の女性の彫刻 / 光を反射している
- Scene: 白い背景 / 女性像 / クリスタル
箇条書き・タグ形式で返すので、そのままメタデータや分類に使える。
NSFW表示にも対応しています。

ここが重要です。
速いだけじゃない。出力が使える。
Gemma3 が「きれいに書く」のに対し、
Qwen3-VL は“仕事ができる”。
■ セットアップ(3ステップ)
- LM Studio を起動
- Vision対応モデル(
qwen/qwen3-vl-4b)をロード
※「目玉アイコン」があるモデルが Vision 対応
※ Vision 対応 の Gemma3 などでも動作しました - このスクリプトを実行する
python vision-tagger.py※ LM Studio が起動していないと接続できません。
※ モデル名はあなたの環境のものに合わせて下さい。
■ 出力される HTML の見方
| 表示 | 意味 |
|---|---|
| respond (ms) | モデルが応答するまでの時間 |
| prepare (ms) | 画像を読み込む時間 |
| total (ms) | 1枚の画像にかかった総時間 |
| NSFW | コード内で制御可能 NSFW_KEYWORDS = [‘裸’,’裸体’,’ヌード’,’全裸’]; |
JSONを眺めていた頃には戻れません。
画像 × 推論 × ベンチマーク が 1画面で一望 できます。
■ 大きい画像の処理はどうなる?
Vision推論は、画像解像度に比例して「リニアに処理時間が増える」わけではない。
理由はシンプルで、
LM Studio が内部で画像を縮小してから推論している
(=巨大画像をそのままモデルに渡しているわけではない)
そのため、800万画素 → 1200万画素 → 2400万画素 と増えても、
応答時間は 緩やかに増える程度。
実測値(Qwen3-VL / RTX3060 で検証):
| 画像サイズ | respond(ms) | total(ms) | 備考 |
|---|---|---|---|
| 1152 × 896 | 1516-2225 | 1424-2306 | Fooocus 生成サンプル |
| 4032 × 3024 | 1817-4684 | 2012-4771 | スマホ撮影 |
※ 数字は実測ログの例(画像によって前後する)
■ なぜ Qwen3-VL なのか?
結論:速いから。
前回の記事(ベンチ比較)でも書いたが、Qwen3-VL-4B は
Gemma3-4B-it より 3〜5倍高速 だった。

■ 発展案(すぐ応用できる)
- フォルダ自動仕分け
- タグ付け + 画像データベース化
- Photo / Assets 管理
Vision推論が 遊びから仕事に変わる瞬間。
■ まとめ
- LM Studio + Qwen3-VL は ローカルで Vision が動く
- 画像タグ付け結果を HTMLで可視化できるツール を公開
- JSONではなく “読めるUI” で結果を見る
Vision は“重いクラウド”じゃなくても動く。
ローカルでできる。高速で。
■ ダウンロード
ライセンス:MIT
ご使用前に、同梱の README.md をご確認ください。
※ご使用は自己責任でお願いします



