AIは文章は量産できるのに、校正にだけ時間が吸われる。しかも機密は外に出せない――。
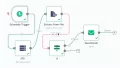
このツールは、書いたテキストを“同じAIにもう一度読ませて直す”ためのローカル校正ワークフローです。LM StudioのOpenAI互換APIで完全ローカル&セキュア。フォルダを渡すだけで、問題がある原稿だけに「修正文」「行差分(.diff.txt)」「判断理由つきレビュー(review.json)」を吐き出します。
例:
「見れません」→「見ることができません」/「Flexbox」→「フレックスボックス(Flexbox)」/「API・テスト・!!!」→自然な表記へ。
しかも コードブロックは一切触らない ので技術記事でも安全。
人は“意味の正しさ”に集中。整形の地雷は、AIが先に片づけます。
なぜ“二度見レビュー”が必要か――まずは「困りごと」から
「書く量」は増えたのに、目視チェックの大半は言語の整形で溶けがち。
人が確認したいのは内容の正しさなのに、実際に直しているのは——
- ら抜き・い抜き:「見れません」「~してる」
- 二重敬語/重ね言葉:「お伺いさせて」「違和感を感じる」
- 表記ゆれ:インタフェース/インターフェース、Flexbox/フレックスボックス
- 全角半角/半角カタカナ/ALL CAPS/!!! の暴発
- コードブロックが壊れる(技術記事あるある)
- しかもフォルダ単位で一括で直したいのに、手作業だと現実的じゃない
ここで効くのが、LLM二度見レビュー。
「書かせる(or 人が書く)→同じLLMにもう一度読ませて直させる→人の最終確認」という流れにすると、人は意味の確認だけに集中できます。しかも本稿のやり方はローカル完結(LM Studio)なので、社内・学術文書でも運用しやすい。
“二度見”で何が変わる?
- 機械が得意な整形(ら抜き、表記統一、全角半角、記号の多重)を先に潰す
- コードフェンスは触らない(
…内は保護) - 修正は最小限に留め、修正文(fixed_text)まで自動で用意
- 変更点は.diff.txtで一目瞭然(校正の証跡になる)
- 問題がある原稿だけ成果物を出力(
--only-problem)
差分の見え方(サンプル)
--- api.txt:original
+++ api.txt:fixed
@@
-インタフェース は接点のこと。ポリモorphismの例もあります。
+インターフェースは接点のこと。ポリモーフィズム(polymorphism)の例もあります。
@@
-これはテストです。
+これはテストです。
@@
-THIS IS IMPORTANT!!!
+重要な点です。
どこを、なぜ、どう直したかが行単位で分かる。人のレビューが一気に楽になります。
3ステップ導入(最短で回す)
ステップ1:LM Studioを起動
- OpenAI互換サーバーをONにしてモデルをロード。
- モデルIDは LM Studio の Models 一覧に出る id をそのまま使います(例:
openai/gpt-oss-20bなど)。 - 接続先(base_url)は
http://localhost:1234/v1。
ポイント:まずは動作安定重視で温度低め(本スクリプト既定は 0.2)。
400 Bad Request が出るモデルは--no-jsonfmtを付けると通ることが多いです。
ステップ2:原稿を置く
- 任意のフォルダに
.txt/.mdの原稿ファイルを入れる(例:drafts/)。 - スクリプト
llm_double_take.pyを同じプロジェクト直下に配置。
project/
├─ llm_double_take.py
├─ drafts/
│ ├─ api.txt
│ ├─ css_intro.txt
│ └─ clean.md
└─ logs/ (自動生成)
ステップ3:ワンライナーで実行
PowerShell(Windows)
python .\llm_double_take.py --in drafts --out reviewed --log logs\review.log `
--provider lmstudio --base_url "http://localhost:1234/v1" --model "<LM StudioのモデルID>" `
--no-jsonfmt --strict --only-problem
Bash(macOS/Linux)
python ./llm_double_take.py --in drafts --out reviewed --log logs/review.log \
--provider lmstudio --base_url "http://localhost:1234/v1" --model "<LM StudioのモデルID>" \
--no-jsonfmt --strict --only-problem
- 出力(問題があったファイルだけ)
reviewed/<name>.review.json… 指摘・checks[]・fixed_text(修正文)reviewed/<name>.diff.txt… 行単位の差分(“どこをどう直したか”が一目)reviewed/<name>.txt… 修正後本文(--dry-run時は出力しない)- (任意)
--notesを付けるとreviewed/<name>.review.md(人手用チェックリスト)
- 問題なしの原稿は 成果物を出さず、
logs/review.logにclean: no issues foundのみ。
.diff.txt の読み方(サンプル)
--- api.txt:original
+++ api.txt:fixed
@@
-インタフェース は接点のこと。ポリモorphismの例もあります。
+インターフェースは接点のこと。ポリモーフィズム(polymorphism)の例もあります。
@@
-これはテストです。
+これはテストです。
@@
-THIS IS IMPORTANT!!!
+重要な点です。
-が元の文、+が修正文。- 用語統一・半角カタカナ→全角・ALL CAPS/記号過多の是正などが行単位で可視化されます。
オプション早見(最初に覚えるのは3つでOK)
--strict:何がOK/NGだったかをchecks[]で見える化--only-problem:問題がある原稿だけを成果物として出力--no-jsonfmt:一部モデルの400回避(response_format非対応対策)
ほか:
--notes(人手レビュー用のMDノート)、--tone formal|casual(文体トーン)、--ext ".txt,.md"(対象拡張子)
よくある詰まり(最短解決)
- 400 Bad Request →
--no-jsonfmtを付ける/モデルIDを正確に - 出力が多すぎる →
--only-problemを付ける - コードが壊れそう → 本スクリプトは
…内を触らない 方針を明示済み - 学術用途 → “スタイル整形の支援であり、内容検証・剽窃チェックは対象外” を本文に明記
“どう動くか”と「.diff.txt」の価値
この章では、何を見て、どう直し、どう見える化するかを整理します。
ポイントは (1) 事前ヒント → (2) ガードレール付きの修正 → (3) 証跡としての差分 の三段構え。
何を検出しているか(主なカテゴリ)
- mixed_kana_english:カタカナと英字が1語に混在(例: ポリモorphism)
- zenhan_mixed:全角/半角の混在(API/AI など)
- halfwidth_katakana:半角カタカナの混入
- punct_marks:
!!!や!?!?の多重、句点のブレ(。/。) - all_caps_misuse:不自然な ALL CAPS(API/HTTP などの例外は許容)
- weird_wording:日本語としての違和感(ら抜き・い抜き・二重敬語・重ね言葉 含む)
- missing_prefix / missing_closing:冒頭/締めの定型句漏れ(必要時のみ)
- term_normalize:用語の表記統一(フレックスボックス(Flexbox) など)
これらの 検出カテゴリは
checks[]に pass/fail で落ちます。NGが1つでもあれば、--only-problem時に成果物を出力。
事前ヒント(プリスキャン)で“見落としを減らす”
実行前に、テキストから軽い規則で疑い箇所を拾い、LLMに「要確認候補」として渡しています。
- 例:
- ら抜き:「見れません」「来れない」
- い抜き:「してる」「なってる」
- 二重敬語:「おっしゃられ」「拝見させて」
- 重ね言葉:「違和感を感じる」「頭痛が痛い」
- 記号多重:
!!!,!?!? - 半角カタカナ:
テスト - 全角英数:
API
LLMに“ここ見て”と合図するイメージ。最終判断は文脈に応じてLLMが行い、過剰修正を避けるよう促しています。
ガードレール(壊さず・最小で)
- コードフェンス保護:
...内は変更しない(改行・インデント含む) - 最小修正:意味改変は避け、表記・体裁・ゆらぎを中心に直す
- 文体トーン:
--tone formal|casualで調整(既定はフォーマル)
技術記事・論文で怖いのは「コードや式が壊れる」こと。“触らないゾーン”を明示して事故を防ぎます。
出力の内訳(人が判断しやすい形)
.review.json:issues[](何をどう直したか)checks[](カテゴリ別の pass/fail)fixed_text(修正後の全文)
.diff.txt:原稿→修正後の行差分(unified diff)- 修正後
.txt:公開用の素体(--dry-runなら出さない) .review.md(任意--notes):人が✔で潰していけるノート
“指摘だけ”でなく“直した全文”を同時に出すのが大事。
最終レビューは.diff.txtと.txtを並べて見ると爆速になります。
なぜ「.diff.txt」が価値になるか
- どこを直したかが一望できる → 人の確認コストが激減
- 修正理由(issues の
explanation)と行差分が対応している - 学術/社内でも校正の証跡として扱いやすい
- Pull Request文化に馴染む → レビュー文化と相性が良い
差分例(再掲)
--- api.txt:original
+++ api.txt:fixed
@@
-インタフェース は接点のこと。ポリモorphismの例もあります。
+インターフェースは接点のこと。ポリモーフィズム(polymorphism)の例もあります。
@@
-これはテストです。
+これはテストです。
@@
-THIS IS IMPORTANT!!!
+重要な点です。
実務での回し方(おすすめフロー)
- 草稿(人 or 生成)を
drafts/に置く - 二度見レビュー実行(第2章のワンライナー)
- Reviewer は
.diff.txtを起点に確認 → 必要なら加筆修正 - OKなら修正後
.txtをサイト/エディタに貼り込み - ログ・成果物は案件ごとに保管 or 破棄(ポリシー次第)
量産でも壊れないやり方です。人の時間は意味の確認に全振りできます。
“品質”をさらに上げたいときの軽い工夫
--strict常用:チームで“何がOK/NGか”を数字で共有--only-problem:成果物を最小化し、差分レビューに集中--notes:紙の赤入れに近い運用がしたいときに- 定型句ON/OFF:
--no-templatesでメディア別の作法に合わせる
ユースケース別レシピ & トラブルシュート
ユースケース別“そのままコピペ”プリセット
学術(学生レポート/修論)
- 目的:言語面の粗取り(内容検証・剽窃は対象外)
- 推奨:
--strict --only-problem --tone formal --notes - メモ:引用や会話体は文脈上自然なら尊重。引用符や出典は維持。
技術ブログ/ナレッジ
- 目的:コードを壊さず可読性UP
- 推奨:
--strict --only-problem --no-templates --ext ".md,.txt" - メモ:
フェンス内は編集しない前提。言語指定(“`js など)も入れておくと安心。
出版・寄稿(媒体テンプレがある)
- 目的:冒頭/締めの作法を漏れなく
- 推奨:
--strict --only-problem --start_prefix "<媒体の定型>" --closing "<締め定型>" - メモ:必要に応じて
--tone formal固定。
社内ドキュメント(議事録・HowTo)
- 目的:表記の粗を一掃して配布前に整える
- 推奨:
--only-problem --no-templates --tone casual - メモ:ログは件数とカテゴリのみ残す運用が楽。
量産バッチ(大量フォルダ)
- 目的:問題のある原稿だけ成果物に
- 推奨:
--only-problem --strict(まずは1フォルダから段階導入) - メモ:日付ごとに
drafts/2025-08-xx/のように分けて回すと管理しやすい。
出力の使い分け(最短でレビューを終わらせる)
.diff.txt:まずはここだけ見る → “どこが直ったか”が一望。- 修正後
.txt/.md:OKならそのまま公開素体に。 .review.json:判断根拠(issues[]/checks[]/fixed_text)を必要なときだけ開く。.review.md(--notes):紙の赤入れ文化がある現場で便利。✔で潰す運用に。
運用Tips(事故らないために)
- 引用・会話体は「意図的口語」として尊重(過剰修正を避ける)
- 記号の多重(!!!/!?!?)は1つに正規化
- 全角英数/半角カタカナは原則排除
- ALL CAPSは略語のみ許容(API/HTTP/JSON等はOK)
- コードブロックは三連バッククォートで確実に囲む(言語指定なお良し)
トラブルシュート(最短解決版)
- 400 Bad Request:
--no-jsonfmtを付ける/モデルIDを正確に(LM Studioの一覧そのまま) - PowerShellの改行でエラー:行継続は バッククォート(
`)。不安なら1行で実行 - 何も出力されない:
--only-problemだと“問題なし”は成果物ゼロ。logs/review.logを確認 - JSON解析エラー:
--retries 3の既定で再試行。改善しなければ--no-jsonfmtを併用 - 文字化け:入力は UTF-8(BOMなし推奨)
- コード内が直されてしまった?:フェンスの閉じ忘れを確認(“` の数が揃っているか)
- diff が見当たらない:そもそも変更なし/“問題なし判定”。
--only-problemを外して一度確認
チーム導入の勘所(小さく始める)
- まずは1フォルダだけで回して出力の質を確認
.diff.txtを起点にレビュー基準を合わせる(何を“直す/残す”か)- OKなら 全ドラフトに拡大。
--strictを常用して数字(pass/fail)で会話 - ログの扱い(保存/破棄)はチームのポリシーに合わせて決める
FAQ と“公正な住み分け”
比較の前提(大事)
- 目的が違えば、最適解も違います。
- ここでは長所を尊重しつつ、「この用途ならコレが向く」という住み分けだけを整理します。
本ツール(LLM二度見レビュー)が向く場面
- ローカル完結で回したい(機密・学術・草稿群の一括処理)
- フォルダ単位のバッチで、問題がある原稿だけ成果物にしたい(
--only-problem) - 修正文(fixed_text)と .diff.txt を同時に欲しい(“どこをどう直したか”の証跡)
- コードフェンスは触らない方針が必須(技術文書)
他のアプローチが向く場面
- リアルタイムにタイピングを支援したい
→ ブラウザ拡張やエディタ連携の“常時アシスト”系が便利 - ルール固定でCIに組み込みたい
→ テキストリンター(ルールを明示して機械判定) - チーム辞書/表記ポリシーの長期運用を中心に据えたい
→ クラウド型の運用サービス(辞書・ルール共有が得意)
どれも「同じ土俵で競う」のではなく、役割が違うだけ。
本ツールは“公開前の前処理をローカルで一気に”が刺さる領域です。
併用パターン(おすすめ)
- 草稿づくり(人 or 生成)
- 本ツールで二度見 →
.diff.txtで粗を一掃 - 仕上げに常時アシスト系で微調整 → 公開
“前処理×仕上げ”の二段構えにすると、人の時間を“内容の正しさ”に集中できます。
よくある質問(FAQ)
Q1. 学術用途で使える?
A. 言語面の整形支援を目的にしてください。内容の真偽や剽窃チェックは対象外。各機関のポリシーに従い、最終責任は執筆者にあります。
Q2. どのモデルが良い?
A. まずは日本語が安定しているモデルで、温度は低め(例: 0.2)。長文はモデルのコンテキスト長に依存するため、章ごとに分けると安定します。
Q3. コードやコマンドが壊れない?
A. **三連バッククォートのコードフェンス内は“触らない”**と明示。閉じ忘れがあると保護されないので、記事側でフェンスをきちんと閉じてください。
Q4. JSONエラーや 400 が出る
A. --no-jsonfmt を付ける(response_format 非対応モデル対策)/--retries で再試行。モデルIDはLM Studioの一覧に出るidを正確に。
Q5. 表記統一の辞書を使いたい
A. まずは本体で“ゆらぎ”を抑え、辞書運用が必要になったら追加モジュールとして拡張するのが安全(記事末の“余韻”参照)。
Q6. 口語や創作文体は直され過ぎない?
A. 文脈上の意図を尊重するよう促しています。気になる場合は --tone casual を試し、.diff.txt で意図しない変更がないか確認を。
Q7. 出力が多すぎて管理が大変
A. --only-problem を常用。問題があった原稿だけ成果物を出すので、レビューの集中度が上がります。
Q8. セキュリティは大丈夫?
A. 本稿の運用はローカル完結が前提。localhost 接続で、ログは件数とカテゴリ中心に。案件のポリシーに合わせて成果物を保管/破棄してください。
未来の余韻
- 追加モジュールとして軽い外部ソース照合(最新語彙・固有名詞の表記確認)をオプトインで載せる構想があります。
- 既定はオフ。ローカル完結が基本という軸は変えません。
- 出典や日付の扱いは、各プロジェクトの方針に合わせて選べる設計を想定。
まとめ & 付録
まとめ
- 二度見レビューの肝は「書いたテキストを、同じLLMにもう一度読ませて直す」。
- 重点は ら抜き・い抜き・二重敬語・重ね言葉・表記ゆれ・全角半角・記号多重。
- 技術文書に必須の コードフェンス保護(
…内は触らない)を明示。 - 成果物は
.review.json(指摘+修正文)/.diff.txt(証跡)/修正後.txt/.md。 - ローカル完結でフォルダ一括処理、問題がある原稿だけ成果物を出力(
--only-problem)。
付録A:ダウンロード
バージョン:v1.0.0 / 更新日:2025-08-30
SHA256: 3b050ab2cacad22be32f97d7f1e704e1f277ec6af54ec0fb66f1b843d93d6c9d
同梱物:
llm-double-take/
├─ llm_double_take.py
├─ samples/ # 入力&出力のサンプル一式(記事スクショ向け)
│ ├─ drafts/
│ ├─ reviewed/ # *.review.json / *.diff.txt / 修正版 *.txt / *.review.md
│ └─ logs/
├─ README.md # 最短手順(記事の簡約版)
├─ CHANGELOG.md
└─ LICENSE # MIT付録B:最小ワンライナー(そのまま実行)
PowerShell(Windows)
python .\llm_double_take.py --in drafts --out reviewed --log logs\review.log `
--provider lmstudio --base_url "http://localhost:1234/v1" --model "<LM StudioのモデルID>" `
--no-jsonfmt --strict --only-problem
Bash(macOS / Linux)
python ./llm_double_take.py --in drafts --out reviewed --log logs/review.log \
--provider lmstudio --base_url "http://localhost:1234/v1" --model "<LM StudioのモデルID>" \
--no-jsonfmt --strict --only-problem
既定の対象は
.txtと.md。フォルダ名は適宜置き換える。
付録C:出力仕様(要点)
<name>.review.jsonissues[]:カテゴリ・該当箇所・修正案・補足checks[]:主要カテゴリの pass/fail(--strict時)fixed_text:修正後の全文
<name>.diff.txt:unified diff(原稿→修正後、行単位)<name>.txt/.md:修正後本文(--dry-runでは出力しない)<name>.review.md:人手確認ノート(--notesで出力)
付録D:主なチェックカテゴリ
mixed_kana_english(カタカナ+英字の混在)zenhan_mixed(全角半角の混在)halfwidth_katakana(半角カタカナ)punct_marks(記号多重・句点ブレ)all_caps_misuse(不自然なALL CAPS)weird_wording(ら抜き・い抜き・二重敬語・重ね言葉など)missing_prefix/missing_closing(冒頭/締めの定型句)term_normalize(用語の表記統一)
付録E:トラブルシュート(早見)
- 400 Bad Request →
--no-jsonfmtを付与/モデルIDを正確に指定 - 出力が多い →
--only-problemを付与 - コードが壊れる → コードフェンス(“`)の閉じ忘れを確認
- 何も出ない → “問題なし”の場合は成果物ゼロ。
logs/review.logを確認 - JSONエラー →
--retries 3で再試行、必要に応じて--no-jsonfmt併用
付録F:ライセンスと注意
- ライセンスはスクリプト冒頭の表記(MIT)に準拠。
- 本ツールは言語面の整形支援を目的とする。内容の真偽・剽窃チェックは対象外。
- 学術・社内の方針に従い、成果物の保存や公開可否を運用する。
(コラム)review.json で“AIの判断理由”が見える
.diff.txt は「どこが変わったか」を示す証跡ですが、review.json は「なぜそう直したか」まで分かるのが強みです。主な構造は以下の3つ。
checks[]:カテゴリ別の合否(例:all_caps_misuse=falseなど)issues[]:具体的な指摘と修正案(type / original / suggestion)fixed_text:修正後の全文(このまま公開素体に)notes:判断のまとめ(ポリシー理由や迷いどころの説明)
サンプル(抜粋)
{
"issues": [
{ "type": "all_caps_misuse", "original": "VBR", "suggestion": "VBR(可変ビットレート)" },
{ "type": "all_caps_misuse", "original": "CBR", "suggestion": "CBR(固定ビットレート)" }
],
"notes": "VBR・CBR は一般略語ではないため、全大文字表記は避け、説明付きでカッコ書きにしました。"
}
この例では、VBR/CBR を“全大文字のまま放置しない理由”まで記録されており、校正ポリシーの説明責任を担保できます。
“読み方”の最短手順
issues[]を見る → 何が・どう直ったかを把握notesを流し読む → 方針/背景説明を確認- 必要に応じて
checks[]で合否の全体感をつかむ - 問題なければ
fixed_textを採用、.diff.txtで差分を最終確認