
はじめに
「GPU支援をフルに使えば、LM Studioでの大規模言語モデルはもっと速くなるはず」
そう考えたことがある人は多いでしょう。
今回の主役は gpt-oss-20B。OpenAIが公開したOSSモデルで、そのパラメータ数は20B(200億)にも及びます。
そして実験台となるマシンは、ミドルクラスながら根強い人気を誇る RTX 3060(12GB VRAM) 搭載PC。
条件はシンプルです。
- モデルをLM Studioで動かす
- デフォルト設定(Before)と、高速化を狙った調整(After)で実測比較する
目的はただひとつ──
「RTX 3060でも、設定を変えれば劇的に速くなるのか?」
しかし、結果は意外な方向に転びました。
高速化を狙ったはずが、まさかの失速。
本記事では、その検証プロセスと結果、そしてなぜそうなったのかを掘り下げます。
テスト環境と条件
今回の検証は、RTX 3060 GPUでgpt-oss-20BモデルをLM Studioにロードし、
デフォルト設定と高速化チューニング設定の2パターンを比較しました。
ハードウェア構成
- GPU:NVIDIA RTX 3060(12GB VRAM)
- CPU:Intel Core i7-8700(6コア12スレッド)
- RAM:32GB DDR4 3200
- ストレージ:NVMe SSD 1TB
- OS:Windows 11 Pro
※ このスペックは、LM Studioで20BクラスのLLMを動かすギリギリ実用的な構成と言えます。
LM Studioのバージョン
- Ver:0.3.22(build1)
モデル
- モデル名:
openai/gpt-oss-20b - 量子化形式:Q4_K_M(4bit量子化)
- ※Q4_K_MはVRAM効率と性能のバランスが良いとされる設定
Before(デフォルト)設定
LM Studio のほぼデフォルト設定です。
- コンテキスト長:4,096
- GPUオフロード:約70%(自動設定)
- 評価バッチサイズ:512
- CPU Thread Pool size:4
- Flash Attention:OFF
- Reasoning Effort:Low(デフォルト)
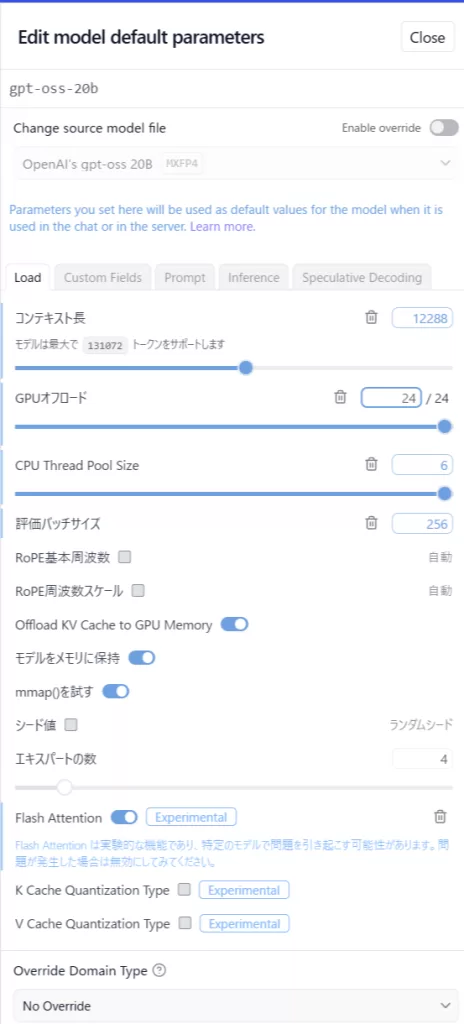
After(高速化チューニング)設定
高速化に効くと思われるパラメータを調整しています。
- コンテキスト長:12,288
- GPUオフロード:100%
- 評価バッチサイズ:256
- CPU Thread Pool size:6
- Flash Attention:ON
- Reasoning Effort:Low(デフォルト)
比較項目
検証では以下の指標を計測しました。
- Tokens/sec(生成速度)
- 総生成トークン数
- 初回トークン待ち時間(秒)
LM Studio のモデルパラメータ調整パネル
「マイモデル」からモデル名の「アクション」の中の歯車アイコンから開くことができます。
検証1:短文タスク(100項目リスト生成)
まずは短文〜中長文タスクでの性能を比較しました。
プロンプトはシンプルに、以下の内容です。
AIでできることを100項目、日本語で番号付きリストにしてください(各項目は短い説明を添える)
このタスクでは、モデルに幅広い分野の知識を呼び出させつつも、1項目ごとの文章量は少なく、生成トークン数は2,000〜3,000程度に収まります。
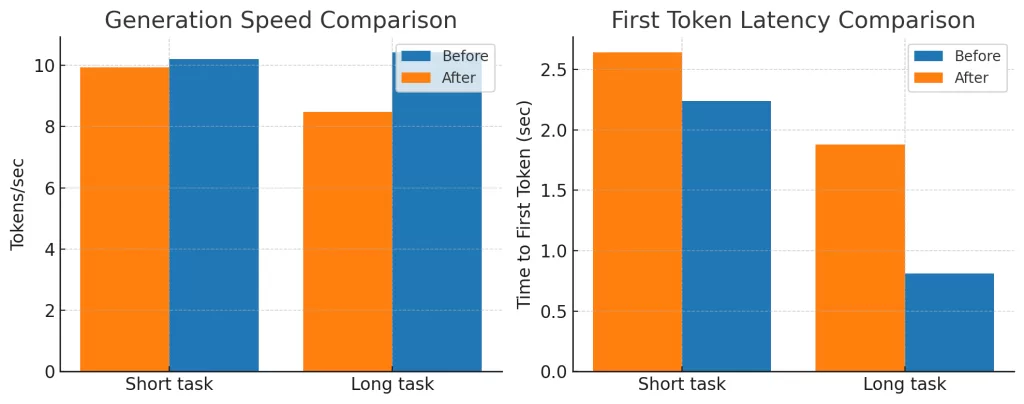
計測結果
| 設定 | Tokens/sec | Total Tokens | Time to First Token (sec) |
|---|---|---|---|
| Before | 10.21 | 3,102 | 2.24 |
| After | 9.94 | 2,331 | 2.64 |
考察
短文タスクでは、After設定(コンテキスト長12k、Flash Attention ONなど)にしても速度は向上せず、むしろ若干低下しました。
特に注目すべきは総生成トークン数が減ったことです(約25%減)。
これはモデルが早めにEOS(文の終了)を発火しており、生成途中で切り上げた可能性があります。
「速くなった」のではなく「生成が短くなった」ために差が縮まって見える場面もある、ということです。
検証2:長文タスク(3,000文字超の小説生成)
次は長文生成タスクで比較しました。
プロンプトは以下のような、物語創作型です。
月面都市を舞台に、複数の登場人物とSF的要素を含む物語を章立てで書いてください(おおよそ3,000文字)
このタスクは、短文リストに比べて生成トークン数が多く、1トークンあたりの処理回数も増えるため、設定変更の影響が顕著に現れやすい条件です。
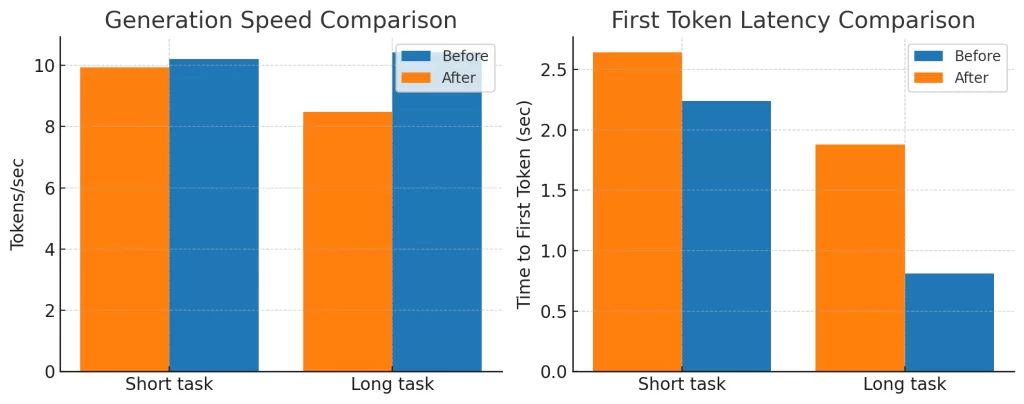
計測結果
| 設定 | Tokens/sec | Total Tokens | Time to First Token (sec) |
|---|---|---|---|
| Before | 10.42 | 2,784 | 0.81 |
| After | 8.49 | 2,454 | 1.88 |
グラフ比較
考察
短文タスクと違い、Tokens/secが約18.5%低下しました。
また、初回トークン待ち時間も 0.81秒 → 1.88秒 と、ほぼ倍増しています。
生成トークン数も約12%減少しており、After設定ではモデルが早めにEOSを発火しやすくなっている可能性があります。
この結果から、今回の高速化設定(コンテキスト長12k、Flash Attention ON、バッチサイズ256、GPU 100%オフロード)は、RTX 3060環境では長文生成に不利であることがわかりました。
結果と考察
今回の比較結果をまとめると、以下のようになります。
| タスク | Tokens/sec Before | Tokens/sec After | 変化率 | Time to First Token Before | Time to First Token After |
|---|---|---|---|---|---|
| 短文(100項目) | 10.21 | 9.94 | -2.6%低下 | 2.24秒 | 2.64秒 |
| 長文(小説) | 10.42 | 8.49 | -18.5%低下 | 0.81秒 | 1.88秒 |
短文タスクでの傾向
- 速度差はごく僅かで、体感ではほぼ変化なし
- ただし総トークン数が減少しており、出力が短くなった可能性が高い
- EOS発火の挙動が変わった影響か、早めに終了する傾向
長文タスクでの傾向
- 速度が約18%低下
- 初回トークン待ちがほぼ倍増し、体感速度の悪化が顕著
- 総トークン数も減少し、生成が途中で終わるケースあり
なぜ長文で失速したのか?
- コンテキスト長12,288のオーバーヘッド
- 長文生成では、生成のたびに全コンテキストを処理するため、長いコンテキスト設定が足かせになる可能性
- バッチサイズ256への変更
- 長文処理では小さなバッチサイズだと計算効率が下がる
- GPU 100%オフロードの転送負荷
- RTX 3060のVRAM帯域では、全レイヤーGPU処理がかえって遅くなる場面もある
- Flash Attention ONによるメモリアクセス増
- モデル・GPU環境によっては、Flash Attentionが必ずしも速度向上につながらないケースがある
結論として、RTX 3060では「高速化設定」が必ずしも速くなるわけではなく、特に長文生成では逆効果になる場合があることが分かりました。
RTX 3060ユーザーへの提言
今回の検証を踏まえ、RTX 3060でLM Studio+gpt-oss-20Bを使う場合の実践的なアドバイスをまとめます。
1. 長文生成ならコンテキスト長はデフォルト維持
- 12,288のような大きなコンテキスト長は、必要なときだけ使う
- 小説や長編記事生成ではオーバーヘッドが大きく、速度低下が顕著になる
- 日常利用では4,096〜6,144程度が無難
2. バッチサイズはむやみに下げない
- バッチサイズを256にすると、RTX 3060では長文時の効率が下がることがある
- 標準の512を維持するか、GPU負荷を見ながら調整する
3. GPUオフロードは100%が最適とは限らない
- RTX 3060のVRAM帯域では、全レイヤーGPU処理が転送負荷になり逆に遅くなる場合あり
- 80〜90%程度のオフロードで、CPUとGPUのバランスを取る方が速いこともある
4. Flash Attentionは環境依存
- モデルやCUDAバージョンによって効果が出ない場合あり
- ONにして遅くなる場合はOFFに戻す判断も必要
5. Q4_K_MやQ4_K_Sなどの軽量量子化モデルを検討
- VRAM 12GB環境では、より軽い量子化モデル(Q4_K_Sなど)で速度改善が期待できる
- 出力品質が大きく低下しない範囲で選択する
まとめ
RTX 3060は20BクラスのLLMを動かせるが、
「フルGPUオフロード+長大コンテキスト+バッチ縮小」の組み合わせは、必ずしも高速化につながらない。
むしろワークロードと設定のバランスが重要で、短文と長文で設定を切り替えるのが賢い使い方だと言える。
まとめと今後の展望
今回の検証では、RTX 3060環境でgpt-oss-20BをLM Studioに載せ、高速化を狙った設定変更が必ずしも効果的ではないことが明らかになりました。
- 短文タスクでは速度差はほぼなし
- 長文タスクでは約18%の速度低下
- 総トークン数も減少し、生成途中でEOSが発火しやすくなる挙動も観測
高速化を目指す場合、単純に「GPUオフロード最大」「コンテキスト長拡大」「Flash Attention ON」にすればよいわけではなく、
ワークロード(短文か長文か)とGPU性能のバランスを見極める必要があります。
今後の展望
- 軽量量子化モデルでの再検証
- Q4_K_SやQ4_K_Mなど、よりVRAM負荷の低いモデルを用いて、速度と品質のバランスを探る
- 設定のプロファイル化
- 短文用、長文用の設定プリセットを用意してタスクに応じて切り替え
- 新世代GPUでの比較
- RTX 40シリーズや将来のRTX 50シリーズでの動作差を検証し、アーキテクチャ依存の要素を洗い出す
最後に
RTX 3060はミドルクラスGPUながら、工夫次第で20BクラスのLLMを動かせます。
しかし「何となく速そうな設定」を入れるだけでは、かえって失速するケースもあります。
本記事の結果が、同じ環境で試行錯誤しているユーザーの参考になれば幸いです。
次はQ4_K_Sモデル登場時に再検証し、そのときこそ真の「高速化記事」をお届けしたいと思います。

