

はじめに(動機)
あなたは画像生成AIを活用していますか?
私は数年前にブームになった頃に少し熱心に触ったくらいで、いまは ChatGPT にブログ用のキャッチ画像をたまに作ってもらう程度です。最近は DALL·E が日本語にもしっかり対応して、かなり使いやすくなってきましたね。
そんな 低めの温度感での付き合いしかなかった私ですが、最近 英単語のクイズゲームを PWA で作っていたときに「画像が入るともっと楽しくなるな」と思い立ちました。
そこで早速、ChatGPT に 90 個の単語リストを渡して画像生成をお願いしてみたんですが……待てど暮らせど終わらない。しかも途中から指数関数的に生成速度が低下していき、当月の利用枠では到底完了しないことが明白に。画像生成は意外と消費トークンが高いんですね。
その場は諦めたのですが、ある時「最近はローカルで画像生成AIを動かしている人が多い」という記事を見かけ、「これだ!」と閃きました。
「クラウド使えばいいじゃん!」と言われそうですが、私の場合はそこまでデザイナー寄りの用途ではなく、アプリを作るときにたまに需要が発生する程度。
従量課金はまだしも、固定費のかかるサブスクリプションサービスはちょっと手が出しづらい。使うときだけガッと生成できる仕組みが理想だったのです。
そんな経緯から今回のテーマ、ローカル画像生成AI環境の構築に挑戦してみた──というわけです。
GTX1060でAI画像生成は可能か?
とはいえ、私の環境はかなり控えめなスペックです。
- CPU: Intel i7 8700
- MEM: 32GB
- GPU: NVIDIA GTX1060
普段使いには何の不満もないスペックですが、生成AIを扱うには、GPUが絶望的に貧弱なイメージ。
しかし、一応有名どころの Stable Diffusion Web UI のシステム要件を見ると、一応 2023年時点では GTX 7xx 以降ならOK となっています。
AUTOMATIC1111’s Stable Diffusion Web UI 推奨環境(2023/08/16 時点)
- 16GB RAM
- NVIDIA (GTX 7xx 以降) GPU(2GB VRAM 以上)
- Linux または Windows 7/8/10/11+
- 最低 10GB のディスク空き容量
とはいえ、実際にネットの記事やフォーラムを見ていると「RTX じゃないとまともに動かない」という話ばかり。
GTX 系なんてお呼びでない感が半端じゃありません(笑)。
もちろん、RTX を買おうかどうか迷ったんですが、RTX 5060 系はトラブル報告も多くて少し不安。
とはいえ、CUDA 系の処理を求めるならやはり NVIDIA 一択なのは間違いありません。
だったら、まずは GTX1060 でどこまでやれるのか試してみよう!
速度が多少遅くても構わない。私の用途としては、1回に 100 ファイル程度生成できれば十分。
そのくらいなら 古めの GTX1060 でもいけるんじゃないか? そう思って今回のチャレンジを始めました。
Fooocus導入
方針は決まったので、あとはソフトウェアの選択です。
目移りするほど選択肢がありますね。
選定の迷い
候補に挙がったのはこのあたり:
- 本家 stable diffusion webui
- WebUI Forge
- Comfy UI
- Stability Matrix
- Fooocus
- SD.Next
- InvokeAI
いざ GTX1060 で試すとなったとき、どのツールを使うかが迷いました。
Stable Diffusion WebUI(AUTOMATIC1111版)も有名ですが、セットアップが結構重そうなイメージ。
しかも、GPUが非RTXだとさらに地雷原という噂も……。
最近は「Fooocus(フーカス)」というツールが話題になっていたので調べてみたところ、
「ほぼノーセットアップで動く」「初心者にも優しいUI」というレビューがたくさん出てきました。
私はパラメータチューンより、お手軽にそれらしい絵がパッと出てくれそうな Fooocus をチョイスしてみました。
導入は本当に簡単だった
実際、導入は驚くほど簡単でした。
公式から Zip ファイルをダウンロードして展開、起動用のバッチファイル(run.bat)を叩くだけ。
CUDA 関連モジュールの地獄のようなセットアップは一切不要。
必要なモジュール類は自動でほいほいインストールされていって、気がつけば UI とご対面です。
これはかなり感動ポイント。
最近のオープンソース系は本当に進化してるなぁと思いました。
Hyper-SD が救世主に
次に問題になるのはスピードです。
遅いことは覚悟していたものの、なるべく速く動作させられるに越したことはありません。
標準セットアップでPerformanceのデフォルトで選択されているのは「Speed」。これで生成してみると、1枚当たり3分超え!想像通りというか、遅いことは覚悟していたとはいえ、これでは…と悲嘆に暮れました。
そこで、最も高速と思われる「Hyper-SD」を選択して実行してみると、今度は1枚あたり30秒程度で生成されるではありませんか?!何やらすごいテクノロジーのようです。
Hyper-SD is one of the new State-of-the-Art diffusion model acceleration techniques
標準設定の「Speed」で3分かかっていた生成が、1/6の30秒程度に短縮!
しかも 品質も十分実用的でした。
少なくとも、私の用途(英単語クイズ用の挿絵)には 全く問題なしでした。
論より証拠。以下をご覧ください。
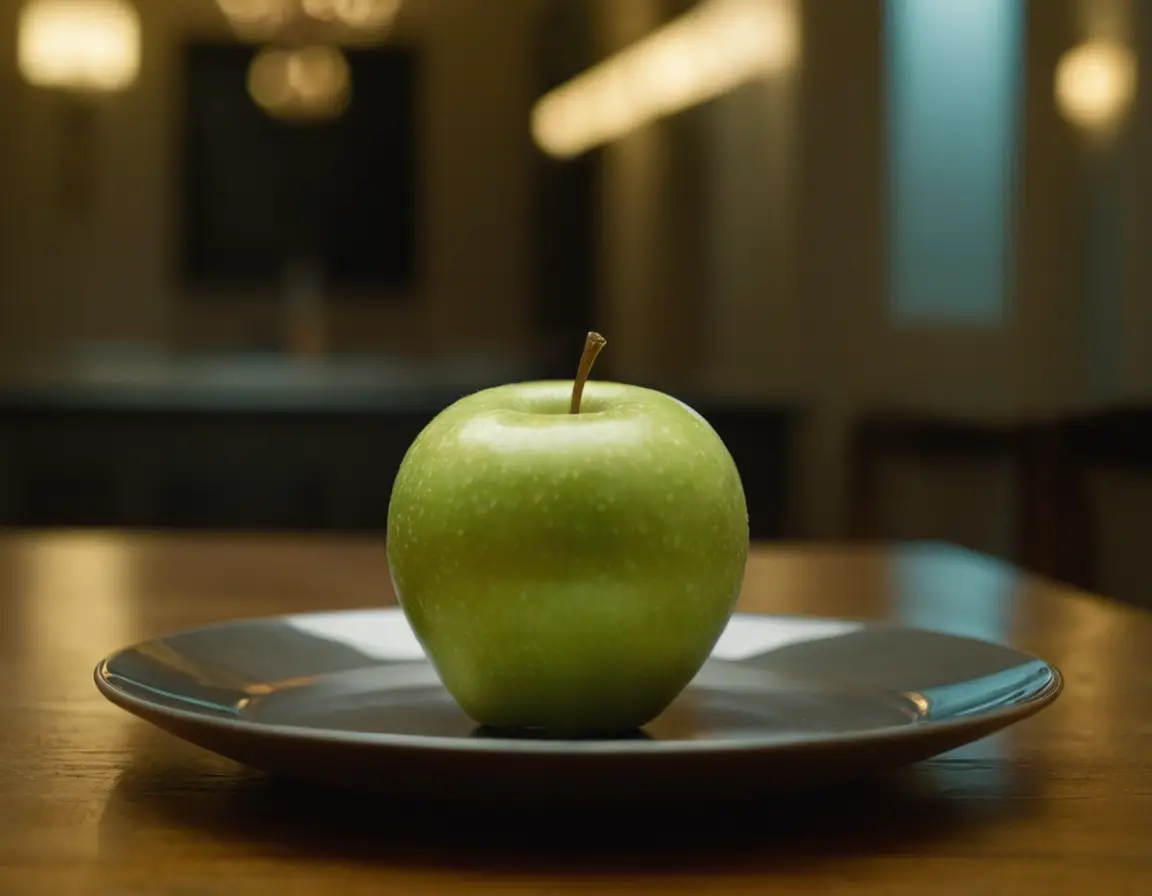

標準セッティングで「apple on the plate」というプロンプトで Speed と Hyper-SD の比較用に生成しました。いかがですか?STEP数が明らかに違うので、同じシード値でも別の絵が出力されますが、出来不出来というより、もはや好みの問題ではないでしょうかね?この品質のものが約6倍のスピードで生成されるんですよ。いやはや、感動的です。
ストレージと VRAM に注意
ここで一点注意点。
画像生成に使用する モデルファイルがかなり大きい(SDXL で 6GB 超え)ので、ストレージの空き容量は必須。しかも、いろいろなモデルを試してみたくなること請け合いで、容量10GBの最低要件は忘れた方がいいですね。
さらに GTX1060 も 3GB版は絶対にやめておいたほうがいいです(VRAM不足でエラーになる可能性が高い)。
6GB版でも Low VRAM モード が使われることが多いですが、それでも動くだけでありがたい。
操作感
実際に Fooocus を動かしてみると、UIは非常にシンプル。
- 真っ白な画面に Prompt 入力欄がポツンとある
- 逆にこれが 初心者にとってはありがたい設計
- Prompt 地獄に陥りにくい
- 必要なときは Model や LoRA の選択も自由にできる(最大5つまで指定可能)
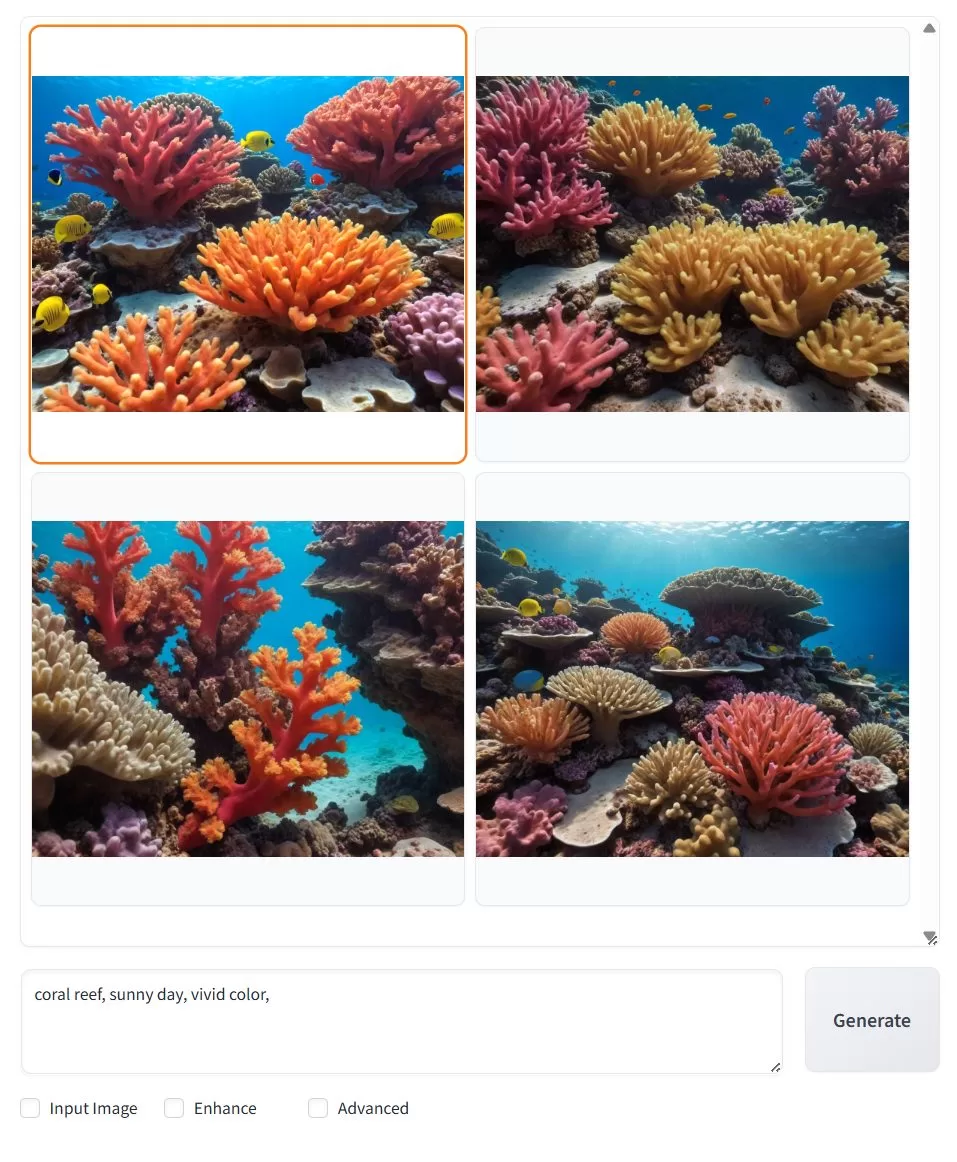
【Fooocus のメイン画面】
究極にシンプルなUI。Stable diffusion のパラメータ満載の画面に圧倒された人も安心。
画面下に prompt を入れて、[Generate] ボタンを押すだけ。
初回の感想と課題
動いた、動いたぞ!!
GTX1060 でも 意外に実用レベルで Stable Diffusion が使えることにまず感動。
「こんな楽しいものが自宅で無制限に使えるなら、人生の時間が足りない……!」と変な焦燥感すら覚えました(笑)。
ただ、すぐに気づいたのは 大量生成は手動では厳しいということ。
例え30秒とはいえ、一枚一枚ポチポチ手で生成するのはさすがにキツい。
これは、Stable Diffusion の特質上、避けがたいもの。
例え、RTX5090を使おうが、キツいことには代わりない。
せっかくローカルで無制限に使えるのだから、キーワードをバンバン放り込んで、バリバリ生成してもらいたい。
そこで、「なんとかバッチ生成の仕組みを組んでしまおう。」
ここからが茨の道でした..。
FooocusAPI導入
自動化したい!
Fooocusが無事動いたのはいいとして……
試しに何枚か画像を手でポチポチ作ってみたんですが、これは無理ゲーです。
私の用途は 英単語クイズ用の画像を大量に作りたいわけで、1単語につき 1〜数枚、トータルでは 数百〜数千枚単位の生成が必要になります。
さすがにこの枚数を 人力クリックで生成して保存して…… なんてやっていたら日が暮れてしまう。
むしろ人生が終わってしまう(笑)。
ここで私は決意しました。
「是が非でも自動連続生成させてやる!」
自動化の選択肢は?
自動化の方法としては、最初は RPA や 画面操作をエミュレーションする方法も考えました。
でも、それって結局 画面が邪魔になるし、PC占有になるし、エラー耐性も低い。
もっとスマートな方法がないかな? と調べてみると……Fooocus に API があるじゃないですか!
しかも バッチ生成向けに設計された v2 API が最近整備されているとのこと。
これは使わない手はない。
しかし、FooocusAPI導入は甘くなかった……
正直、Fooocus があまりにも簡単に導入できたので油断してました。
FooocusAPI の導入は、まあ、控え目に言って、地雷の宝庫です。
- CUDA / torch バージョンの罠
→ 公式の手順通りやっても動かない環境がちらほら - Python環境の依存関係がかなりきつい
- コンパイルエラーが多発(Visual Studioのバージョン問題にハマる人多数)
- 「FooocusAPIは Fooocus 本体とは別にセットアップが必要」という構造にまず混乱
- モデルファイルの扱いも要注意 → Fooocus 本体と API 側でパスや格納場所がズレるとエラー地獄に
私の場合、ChatGPT先生がなかったら絶対に途中で心が折れてました。
普通にググっても断片的な情報しかなく、トラブルの特定がめちゃくちゃ大変。
眠くなって、コマンド打ち間違いなんかの凡ミスも連発..。ChatGPT先生にエラーコードを丸投げすることに変な快感を覚えるほどでした。
1日近く格闘して、ようやくAPIが正常起動。
「API使うのに Fooocus 本体は要らない」という事実にも途中で気づいて軽く混乱(笑)。
動いたときの感動
苦労の末、初めて API 経由で 1枚目の画像が自動で生成されたときの感動はひとしお。
API が動き始めたら、あとは 自分でバッチ処理のスクリプトを組むだけ。
キーワードリスト → Prompt に組み込み → API に投げる → 保存するという流れが組めれば、後は回すだけ。
ここから バッチ生成の実装に入りました。
(……が、これもまた一筋縄ではいかなかったのです。)
いよいよ本丸のバッチ処理実装へ
APIが動いた、次はバッチだ!
FooocusAPI が ようやく動いたので、次に目指すは 大量自動生成。
最初はとりあえず Python のコードを手書きで API に投げていたんですが、90ワード分、手で1回ずつやるなんて無理ゲー。
せっかく自動化できる環境ができたのだから、まとめて全部投げて勝手に生成 → 保存 → 一覧化 までやりたい。
この時点でもう「英単語画像製造マシン」を作る気満々になってました。
バッチ処理の基本設計
方針はシンプル:
1️⃣ キーワードファイル(keywords.txt) を準備しておく
2️⃣ キーワードを1行ずつ読み込み
3️⃣ Prompt テンプレートに組み込んで API に POST
4️⃣ 返ってきた画像URL(ファイルパス)からローカルに保存
5️⃣ ついでに HTML も生成して、後からブラウザで確認できるようにする
コードのイメージはこんな感じ
import requests
import json
FOOOCUS_API_URL = "http://localhost:8888/v2/generation/text-to-image-with-ip"
with open("keywords.txt", "r", encoding="utf-8") as f:
keywords = [line.strip() for line in f.readlines() if line.strip()]
for keyword in keywords:
prompt = f"Line art of {keyword}, outlines, no colors, white background coloring page style"
params = {
"prompt": prompt,
"performance_selection": "Hyper-SD",
"aspect_ratios_selection": "1024*1024",
"async_process": False
}
response = requests.post(FOOOCUS_API_URL, data=json.dumps(params))
result = response.json()
image_url = result[0]["url"]
print(f"Generated image for {keyword}: {image_url}")
※エラー処理など、コードはかなり省略しています
実装で意識したこと
- 1単語1枚ずつ → ループで順番にAPIコール
- 保存時のファイル名はキーワードから自動生成(後で教材で使いやすい)
- 失敗時のエラー処理 → ここ大事。たまに API 側でタイムアウトが発生する
- HTML 出力 → 一覧で見れた方が楽しいし確認もラク。FooocusAPIではStableDiffusionで生成されるHTMLは出力されない。
実際に 90ワード生成してみた
さて、実際に 90ワード分の 英単語リストを流し込んでバッチ生成を実行!
→ 壮観でした。
→ 途中エラーもなし、1枚あたり平均30秒程度、合計で1時間くらいで完走。
→ 出力された画像はこんな感じ


















これ、PWAの教材用に画像付きクイズを作るならもう完全に現実的なワークフロー。
しかもローカルで生成してるから、コストもゼロ(※電気代を除く)。最高です。
ここまで来て思ったこと
- GTX1060 でも Hyper-SD が強力すぎて全然実用になる
- FooocusAPI の組み合わせで 手動操作は完全に不要にできた
- Prompt の工夫次第でさらに品質UPできそう(これが次なる沼……)
ちょっとした余談(と言い訳)
ちなみに途中で「本家の Stable Diffusion WebUI には最初から API が用意されている」ということにも気づきました。
確かにそちらの API を使えばより細かい制御や高機能な操作も可能です。
ただ今回は、Fooocus の UI が初心者に非常にとっつきやすく、私自身の用途(教材用の大量生成)でも十分な品質が得られていたので、あえて Fooocus 環境を伸ばす方向に振りました。複数環境を維持するのも面倒ですしね。
加えて、FooocusのStyleというのが抜群に便利です。これは、APIからも利用することができるので、共存のシナジーもあります。Styleを指定することで、裏で Negative prompt を勝手に発行してくれるご親切設計がFooocusの持ち味です。凝り性な方は、API経由ならば、Fooocusでは指定できない Negative prompt も確定的に設定が可能です。
さらに言えば、ローカル環境で Fooocus API+バッチ処理がしっかり動いていたので、無理に別環境に切り替える手間を増やす必要性を感じなかったというのも正直なところです。
……まあ、この記事のネタ的にも「Fooocus API のバッチ化」は面白かったというのも理由の一つ、ということで(笑)。
実際の生成例(英語クイズ用画像)
さて、ここからは 実際に生成した画像の一部をご紹介します。
今回、試しに 英単語90ワード をバッチ処理にかけて生成してみました。
1ワードにつき1枚ずつ生成し、画像は 1024×1024 のモノクロ画像になるようにPromptを工夫したんですが、たまにカラー映像があるのはご愛敬。
Hyper-SDのおかげで1枚あたり30秒前後、合計で約1時間程度で全件完了。
GTX1060でも十分戦えるという手応えがありました。
では、いくつかピックアップしてみましょう。
おもしろい傾向が見えますね。
生き物系

動物などは、無難な仕上がりです。魚だけ線画っぽくはなっています。サルとブタはカラーですね。
まぁ、この写真が何かをクイズの選択肢から認識できれば十分なので、問題ありません。
物体系


こちらも、クイズに利用する分には問題ないでしょう。
どうしても、色を付けたい瞬間があるのでしょうね(笑
形容詞系



形容表現は難しいですね。個別にpromptを調整しないとダメかもしれません。ただ、共通の prompt からの生成と思えば十分及第ですよね。
sad の人は、涙の一つも流してくれれば..と思わずにはいられない。
angry のおじさんは好き!
色系




クイズの選択肢から推測することは可能なレベルではありますが..
数字系








やばいのはここ!ほぼそのまま使えない感じです。
まともに使えそうなのは one と four くらいです。
ten は何だか分かりませんし、six に至ってはなぜか全員全裸で、もはやエロ画像..。しかも6人ではなく、3人という大惨事(笑)。two も何だか百合っぽい..。
これは、数字は確実に手動で生成しないとダメですね。
バッチ処理では、こうした思いもよらない画像が出てくる怖さがありますから、みなさんも公開前には必ずチェックしましょう!
生成してみて思ったこと
全体として:
- Fooocus + Hyper-SD の組み合わせは、教材用の挿絵に十分すぎるクオリティ。
- 英単語というシンプルな対象に対しては、Prompt のちょっとした工夫だけでかなり良い結果が得られる。
一方で:
- どうしても1部の単語は「意図と違う絵」になるものがある。
👉 Negative Prompt などを工夫していけばさらに精度は上げられそう。
👉 これは 今後の「Prompt職人」沼の入り口だなと感じた(笑)。
結論
教材用の画像をAIで一括生成するのは、今や本当に現実的な選択肢。
しかも、古めの GTX1060 の環境でも十分実用的に回せる。環境が貧弱だから、バッチ処理落ちとかも覚悟していたけど、一晩回して実測1000画像生成もOK。
「絵が作れないから教材に画像が入れられない」なんて時代はもう終わった。
今は誰でも、ちょっとした工夫とバッチ処理の力で、自分だけの教材素材を作れる時代なのだ。
願わくば、20年ほど時間を巻き戻したい(笑)
FooocusAPIの出力仕様について【ちょっとした補足】
ちなみに、FooocusAPI の出力画像は現状「PNG固定」です。Fooocusではwebpなども指定は可能なのですが。
API 側で「JPEG で出してほしい」とか「品質パラメータを指定する」ようなオプションは 現時点(v2 API)では用意されていません。
これは元々の Fooocus の設計が:
- 画質優先
- 編集や再利用を前提(後からさらに加工するユーザーが多いため)
という思想で作られているためです。
そのため教材用・Web用など「軽い画像が欲しい」用途の場合は、後段でPNG→JPEGやAVIFへの変換を行うのが一般的な運用になっています。
PNG → JPEG 変換の例【コピペでそのまま使えるコード】
私の場合は、教材用途なので1MBクラスのPNGはさすがに重すぎ。
そこで、JPEGで軽量化して使うようにしています。
変換にはPythonの Pillowライブラリ を使えば簡単です。
以下のコードをコピペして実行すれば、PNGをJPEGに一括変換できます:
import os
from PIL import Image
INPUT_DIR = "generated_images"
OUTPUT_DIR = "generated_images_jpeg"
os.makedirs(OUTPUT_DIR, exist_ok=True)
TARGET_EXT = ".png"
JPEG_QUALITY = 75
for filename in os.listdir(INPUT_DIR):
if filename.lower().endswith(TARGET_EXT):
input_path = os.path.join(INPUT_DIR, filename)
output_filename = os.path.splitext(filename)[0] + ".jpg"
output_path = os.path.join(OUTPUT_DIR, output_filename)
print(f"Converting {input_path} -> {output_path}")
try:
with Image.open(input_path) as img:
img = img.convert("RGB")
img.save(output_path, "JPEG", quality=JPEG_QUALITY, optimize=True)
except Exception as e:
print(f"Error converting {filename}: {e}")
print("✅ JPEG Conversion complete!")
👉 実際にこのコードで90枚の画像を一括変換 → 1MB → 約100KB程度に圧縮できました。
Web用・PWA用でもスムーズに読み込めるサイズ感になります。
ご参考まで。
FooocusとFooocusAPIの共存
先ほど言いましたが、FooocusAPIはFooocusをインストールせずとも利用することができます。しかし、私は共存させて使用しています。大雑把に言えば、「同一プロンプトの大量生成はFooocus」で、「個別ワードの大量生成はFooocusAPI」という使い分けが便利なのですが、他にも次のような理由もあります。
- バッチ生成前の prompt のテストにはFooocusのGUIを利用するのが便利
- 巨大なモデルファイルなどはFooocusAPIと共有可能
実際、Fooocusの特長であるStyle(280近くのプリセット)などはAPIからもコールできるのですが、何が何だか到底頭に入ったものではありません。FooocusのGUI上では、Styleごとの特性を表すサムネを見ることができるので、そちらでチェックをしてからAPIのパラメータを決めています。
ちなみに、Fooocusの生成数上限設定は32になっていますが、これは config.txt に以下を入れておけば上限突破が可能です。
"default_max_image_number": 1024,まとめ
というわけで、GTX1060 でも FooocusAPI を使って教材用画像のバッチ生成が十分実用になるという話を、今回は実体験をもとに紹介してみました。
途中いろいろな罠や課題もありましたが(笑)、結論としては「やってよかった」「これは武器になる」と感じています。
今回のポイントを振り返ると:
✅ Fooocus 本体は とても導入が簡単で、初心者にも優しい
✅ FooocusAPI の導入は やや地雷原 → だが乗り越えれば超強力な自動生成環境が手に入る
✅ GTX1060 でも Hyper-SD を使えば 教材用途には十分な速度・品質が実現できる
✅ Prompt チューニングは 永遠の沼 → だがそれも含めて楽しい領域
✅ 出力は PNG 固定 → JPEG/AVIF変換は別途行えばOK(記事内でコードも紹介済み)
✅ ストレージは無限になくなる!楽しそうな model やらのファイルは超巨大..
今後に向けて
今回の構成はすでに 教材用画像の制作環境としては十分に実用的ですが、次は:
- モデル常駐化 fork版Fooocus の導入(これでさらにバッチ処理速度UPが狙える)
- Promptチューニングの強化(Negative Prompt や LoRA の積極活用)
- AVIF対応による画像サイズ最適化(よりモダンなWeb配信対応へ)
……など、さらに改善の余地は多く残されています。
最後に
もしこの記事を読んで:
「GTX1060じゃ無理かと思ってたけど、やってみようかな」
「FooocusAPIって便利そうじゃん」
……と少しでも思ってもらえたなら、とても嬉しいです。
AI画像生成は「最先端の人だけのもの」ではなく、手持ちの環境でも工夫次第で大いに活用できる時代になっています。
この記事がその一つの例になれば幸いです!

