

スキャンしたPDF、スクリーンショット、写真で撮った書類。
それらを「正確にテキスト化したい」という需要は、今も昔も変わらない。
一方で、近年の生成AIブームによって「画像も読めるLLM(VLM)」は一気に身近になった。しかし、実務で使うとすぐに気づく。
- 意味は分かるが、文字を正確に拾うのは苦手
- 表や数式、帳票レイアウトはそれっぽく要約されてしまう
- 「1文字も落とさず抜く」用途には、まだ不安が残る
つまり、汎用VLMとOCRは役割が違うという話だ。
そんな中で登場したのが、OCR特化のVLM「GLM-OCR」である。

GLM-OCR は何がすごいのか
公開されているベンチマークを見ると、GLM-OCRはかなりはっきりしたポジションにいる。
- Document Parsing(OmniDocBench v1.5):94.6
- Text Recognition(OCRBench Text):94.0
- 数式認識(UniMERNet):96.5
- 表認識(PubTabNet / TEDS):85.2 / 86.0
- 情報抽出(Nanonets-KIE):93.7
- 手書きフォーム:86.1
比較対象には PaddleOCR-VL、MinerU、dots.ocr、さらには Gemini 3 Pro や GPT 系の汎用VLMも並んでいるが、純OCR・ドキュメント解析系のタスクでは、ほぼトップクラスのスコアを出している。
ここから分かるのは、GLM-OCRは
「画像の意味を理解するモデル」ではなく、
「文書を正確に読むためのモデル」として最適化されている
という点だ。
請求書、論文PDF、表、数式、帳票、スキャン書類。
こうした「後段でデータ処理に回したい文書」を扱うなら、汎用VLMよりも専業OCRモデルのほうが正解になる。
そして Ollama で“雑に”使える時代
面白いのは、これだけ本気のOCRモデルが、Ollama経由でほぼワンコマンド起動できる点だ。
ollama run glm-ocrあるいは、
ollama run glm-ocr Text Recognition: ./image.pngこれだけで、
- モデルが未インストールなら自動ダウンロード
- ローカルに展開
- そのまま画像を渡してOCR実行
という流れが一気に通る。
ターミナルに画像ファイルをドラッグ&ドロップすれば、そのパスがそのまま入力に使える。
体験としては「CLI版のChatGPTに画像を投げる」感覚にかなり近い。
数年前なら、
- Python環境構築
- CUDA周りの調整
- ライブラリ依存関係地獄
- モデルの手動ダウンロード
- サンプルコード修正
- VRAM調整
といった“儀式”を経て、ようやく試せるのがOCR系モデルだった。
それが今は、
ollama run glm-ocr ./scan.png
で終わる。
AIモデルの「道具化」が、かなり露骨なレベルまで進んできている。
実務での使いどころ
GLM-OCRの立ち位置はかなり明確だ。
- PDFスキャンのテキスト化
- 論文・技術資料からの数式・表の抽出
- 請求書・帳票・フォームの構造化
- KIE(情報抽出)パイプラインの前段OCR
- 画像ベース資料のデータ化・検索用インデックス化
こうした用途では、
- 「意味を要約してほしい」→ 汎用VLM
- 「正確に文字と構造を抜いてほしい」→ GLM-OCR
と役割分担するのが現実的だろう。
日本語はどうか?
正直なところ、ここは要検証だ。
ベンチマークの多くは英語・数式・構造化文書中心なので、日本語縦書きや和文帳票、崩れたスキャンなどでは挙動が変わる可能性は高い。
「日本語はダメダメかも」という懸念は、わりと健全な疑いだと思う。
ここは、Ollamaで簡単に試せる以上、
試してみるのが一番早い。
実地検証
検証環境
今回の検証は、ローカルPC上で Ollama を使用し、glm-ocr モデルを実行して行った。
現時点では安定版では動作せず、Release Candidate(RC)版の Ollama を使用している。
実行コマンドは公式ドキュメントに記載されている以下の形式を使用している。
Text Recognition:テキスト抽出Table Recognition:表構造の抽出Figure Recognition:図中テキストの抽出
入力は PNG 画像ファイルをそのまま渡し、出力は標準出力の結果を確認した。
特別な前処理や後処理は行っていない。
公式ドキュメントより:
使用法
テキスト認識
ollama run glm-ocr Text Recognition: ./image.png
テーブル認識
ollama run glm-ocr Table Recognition: ./image.png
図形認識
ollama run glm-ocr Figure Recognition: ./image.png順に試す。
テキストの認識テスト
単純なテキストは良好な認識結果。日本語でも安定感は抜群。

出力結果
ollama run glm-ocr Text Recognition: ./01.png
Added image ‘./01.png’
要点
- 東芝は HAMR と MAMR の両輪で 30TB超HDD を実証(32TB/31TB)。
- Seagate は HAMR 一筋で 30TB超を市販化、世界初の実用化を実現。
- 東芝は SMR、Seagate は CMR と方式の違いがある。
- HDD の転送速度は頭打ち、キャッシュ増量が主な改善手段。
- プラッター枚数も限界に近く、今後は 記録方式の革新 が勝負。
- ソニーも HAMR 用半導体レーザーを Seagate と開発、日本勢の技術が裹方でも活躍。
- HDDは速度ではSSDに劣るが、大容量・低コスト・長期保存の需要で今後も重要な役割を担う。
テーブル(表)の認識テスト
次に表の認識を試す。
罫線付きの統計表に対しても、行・列の構造を保ったまま内容を抽出でき、数値や見出しの読み取り精度も高い。
少なくとも「画像の表をデータとして扱える形にする」という目的においては、かなり安定した挙動を示す。
一方で、このモードはあくまで 「表そのものの抽出」に特化しているため、表の外側にあるタイトルやキャプション、本文との関係までは考慮しない。
つまり、「ページ全体を理解する」というよりは、表領域だけを切り出して処理する職人芸に近い。
用途を「表データの取り込み」に割り切るなら十分に実用的で、帳票や統計資料のデータ化用途では素直に強い印象を受ける。
引用元: 総務省統計局
「午(うま)年生まれ」と「新成人」の人口-令和8年 新年にちなんで- (「人口推計」から)
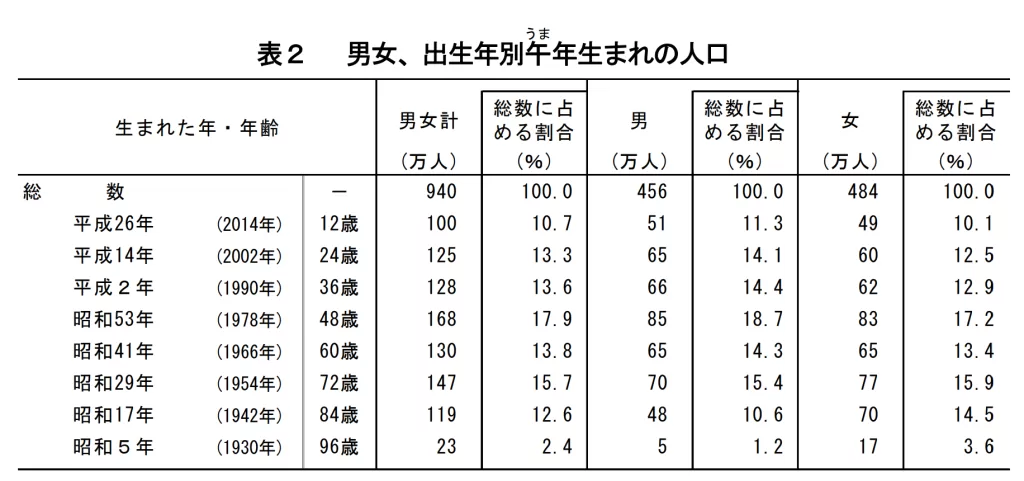
「午(うま)年生まれ」と「新成人」の人口-令和8年 新年にちなんで- (「人口推計」から)
出力結果
| 生まれた年・年齢 | 男女計 (万人) | 総
数に占める割合 (%) | 男 (万人) | 総数に占める割合 (%) | 女 (万人) | 総数に占める
割合 (%) | ||
|---|---|---|---|---|---|---|---|---|
| 総数 | 一 | 940 | 100.0 | 456 | 100.0 | 484 | 100.0 | |
| 平成26年 | (2014年) | 12歳 | 100 | 10.7 | 51 | 11.3 | 49 | 10.1 |
| 平成14年 | (2002年 ) | 24歳 | 125 | 13.3 | 65 | 14.1 | 60 | 12.5 |
| 平成2年 | (1990年) | 36歳 | 128 | 13.6 | 66 | 14.4 | 62 | 12.9 |
| 昭和53年 | (1978年 ) | 48歳 | 168 | 17.9 | 85 | 18.7 | 83 | 17.2 |
| 昭和41年 | (1966年) | 60歳 | 130 | 13.8 | 65 | 14.3 | 65 | 13.4 |
| 昭和29年 | (1954年 ) | 72歳 | 147 | 15.7 | 70 | 15.4 | 77 | 15.9 |
| 昭和17年 | (1942年) | 84歳 | 119 | 12.6 | 48 | 10.6 | 70 | 14.5 |
| 昭和5年 | (1930年 ) | 96歳 | 23 | 2.4 | 5 | 1.2 | 17 | 3.6 |
図形の認識テスト
最後に図形の認識を試す。
グラフや図の中に書き込まれた数値や注釈テキストも問題なく読み取れる。
軸ラベル、凡例、注記なども含めて、画像内の文字情報は一通り拾ってくれる印象だ。
一方で、グラフの形状そのものを解析して「棒の高さから数値を推定する」といった処理までは行わない。
あくまで 「図の中に書かれている文字を読むためのモード」 と考えるのが現実的だろう。
それでも、日本語の図表・統計資料を相手にここまで安定して文字情報を回収できるのは十分に実用的で、
資料の下処理やデータ化の入口としてはかなり強力な部類に入る。
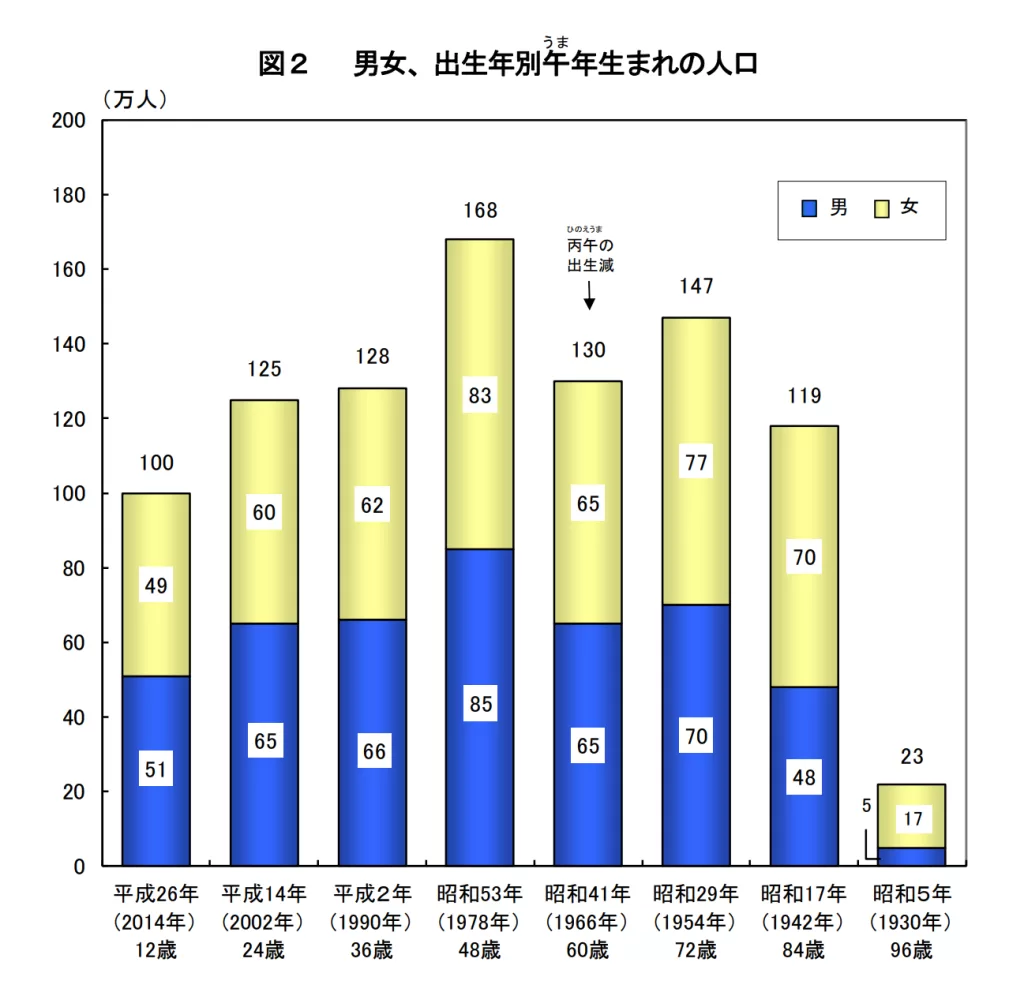
図2 男女、出生年別午うま年生まれの人口
出力結果
PS D:\OCR\GLM-OCR> ollama run glm-ocr Figure Recognition: ./03.png
Added image ‘./03.png’
図2 男女、出生年別午年生まれの人口
(万人)
200
180
160
140
120
100
49
125
128
168
ひのえうま
丙午の
出生減
83
130
147
100
60
62
51
65
66
85
65
77
70
60
40
20
23
17
平成26年
(2014年)
12歳
平成14年
(2002年)
24歳
平成2年
(1990年)
36歳
昭和53年
(1978年)
48歳
昭和41年
(1966年)
60歳
昭和29年
(1954年)
72歳
昭和17年
(1942年)
84歳
昭和5年
(1930年)
96歳
まとめ
GLM-OCRは、OCR・ドキュメント解析に特化したVLMとして見ると、現時点でもかなり完成度の高いモデルだ。
汎用VLMのように「それっぽく理解する」方向ではなく、あくまで 「正確に読む」ことに寄せた設計で、テキスト・表・図それぞれのモードも用途どおり素直に機能する。
実地に日本語資料で試してみても、少なくとも活字・数値・表構造の認識精度は安定しており、「日本語だから厳しいだろう」という先入観はいい意味で裏切られた。
一方で、表とキャプションの自動結合や、図の構造理解までを万能に任せるのはまだ現実的ではなく、得意領域を割り切って使うのが賢い付き合い方だと感じる。
それでも、Ollama 経由でほぼワンコマンドで試せて、このレベルの結果が出るのは素直に強い。
JSONのような中間形式を挟めば、実務パイプラインにも無理なく組み込める。
AIは「考える存在」から、「雑に呼び出して、確実に働かせる道具」へ。
GLM-OCRは、その変化を実感させてくれる、かなり実務寄りの一例だ。



