ローカルLLM環境が一通り揃うと、次に欲しくなるのは「自然な入力」だ。
キーボードではなく、考えたまま話しかける。
スマートフォンでは当たり前になったこの体験を、そのままOpen WebUIでも再現できそうに見える。
実際、Open WebUIは音声入力に対応している。
LM Studioと組み合わせれば、ローカル環境だけで完結する“音声AI”ができそうだ。
少なくとも、画面を見ている限りは。
だが、日本語で試した瞬間、その期待はあっさり裏切られる。
音声は認識されるが、文章にならない。
待たされる。
そして、どこが悪いのか分からない。
STTの精度か。
モデルの問題か。
設定ミスか。
あるいは、自分の勘違いか。
手元には、そうやって行き場を失った検証ログが約3.5万字分残った。
この記事は、そのログを読み返しながら
「何が問題で、どこを直せば一気に解決するのか」
その最短ルートだけを抜き出した記録だ。
結論から言えば、
Open WebUI × LM Studioの日本語音声入力は、そのままでは使い物にならない。
だが、正しい場所に手を入れれば、驚くほどあっさり実用レベルに到達する。
その差は、設定一つ分だ。
なぜ音声入力なのか
スマートフォンでLLMを使うとき、キーボード入力はすでに主役ではない。
多くの人は音声で話しかけ、考えをそのまま投げる。
Open WebUIも音声入力に対応しており、ローカルLLM環境でも「それ」ができそうに見える。
ところが、実際に日本語で使おうとすると、期待は簡単に裏切られる。
検証環境
今回の構成は以下の通りだ。
- TrueNAS Apps 上の Open WebUI
- LM Studio(GPU推論)
- モデル:lfm2-2.6b-exp
- LAN内公開(PC・スマホからアクセス)
ごく一般的な「ローカルLLMを触っている人」の環境だと思っていい。
RTX3060で会話とSTTをやることになったが、負荷的には全く問題はかった。
サーバのCPUは Pentium G4560 + HDD 環境だが、Redis が効果的に機能していて、とても快適に使えた。
TrueNASのAppから簡単インスト―ルできる
使用するLLMモデルは、会話のテンポを重視して、LFM2-2.6B-Exp-GGUF
Open WebUI標準の音声入力は、なぜ使い物にならないのか
結論から言うと、日本語では実用にならない。
症状ははっきりしている。
- 音声入力後、認識までに数秒待たされる
- 文章が途中で切れる
- 単語が化ける
- 文として成立しない
英語ならまだ誤魔化せるが、日本語では破綻が露骨だ。
この状態でLLMに投げても、返ってくるのは「それっぽい誤解答」になる。
体感としては、Androidの音声入力が10年以上前に戻ったような感覚に近い。
HTTPS必須という、もう一つの罠
音声入力には Secure Context(HTTPS)が要求される。
LAN内で http://IP:port のまま Open WebUI を公開すると、
マイク周りで挙動が不安定になったり、そもそも許可が通らなかったりする。
TrueNAS Apps を正規にSSL化するのは、それなりに面倒だ。
ここは実務的に割り切り、Chrome / Edge の設定で
HTTPを擬似的に安全なオリジンとして扱う方法を使った。
これは回避策であって本質的な解決ではないが、先へ進むためには十分だ。
すぐ試せる現実的な回避策
音声入力まわりでまず詰まるのが、HTTPS(Secure Context)問題だ。
これはOpen WebUI固有の話ではなく、ブラウザがマイク入力に課している制約そのもの。
TrueNAS Appsを正攻法でSSL化することもできるが、
検証段階でそこに時間を溶かすのは、はっきり言って無駄が多い。
そこで、まずは「試すための最短ルート」を通る。
Chromeの例外設定を使う(最速・検証向け)
Chrome / Edge を使っているなら、これが一番早い。
![Google Chromeの[Insecure origins treated as secure]設定のキャプチャ。これで、疑似的にHTTPSの挙動を得られる。](https://b.aries67.com/wp-content/uploads/2026/01/image-32.webp)
- アドレスバーに以下を入力
chrome://flags/#unsafely-treat-insecure-origin-as-secure- 「Enable」に変更
- 下部の入力欄に、Open WebUIのURLを指定
http://192.168.1.220:31028- Chromeを再起動
これだけで、そのHTTP URLは HTTPS扱い になる。
この方法の位置づけ(重要)
- あくまで ローカル検証用
- 評価・動作確認には 十分
- 商用運用・常用は NG
だが、今回の目的は
「Open WebUIの日本語音声入力が成立するか」を見極めることだ。
その意味では、これ以上ない近道になる。
リバースプロキシでHTTPS化するのが王道ではある。
だが、検証フェーズでいきなりここに手を出すと、
「証明書設定大会」が始まる。
今回は目的ではないので、深入りしない。
External Tools にSTTをつなごうとして失敗した話
Open WebUIには「External Tools」という、いかにもそれらしい設定項目がある。
STTのURLを指定したくなるのは自然な流れだ。
しかし、ここは罠だった。
- OpenAPI前提の挙動
/openapi.jsonを探しに行く- 音声入力のバックエンドとしては使われない
- 設定が保存できない場合すらある
UIは「それっぽい」が、音声入力パイプラインとは別物だった。
ここで時間を溶かす人は多いと思う。
正解ルート:Faster WhisperをWebAPI化し、環境変数で刺す
解決策はシンプルだった。
- Faster Whisper を FastAPI + Uvicorn で WebAPI 化
- GPUで推論
- Open WebUI(TrueNAS Apps)の
Additional Environment Variables に STT のURLを指定 - Open WebUI を再起動
![Open WebUI(TrueNAS Apps)の[Additional Environment Variables]にSTTのURL[STT_API_BASE_URL]を入れる。](https://b.aries67.com/wp-content/uploads/2026/01/image-33.webp)
これだけで状況が一変する。
- 音声認識が即時に返る
- 日本語が文として成立する
- LLMに渡る入力が「まとも」になる
体感レベルでは、Androidの音声入力と同等まで一気に跳ね上がった。
ここで初めて、「音声でLLMを使う」という体験が成立する。
OpenWebUI側は、”音声テキスト変換エンジン”をデフォルトからウェブAPIに変更すればいい。

激変する日本語の音声認識の精度
音声入力:「日本の少子化問題にどのように対応すべきですか?」
標準STT の認識結果
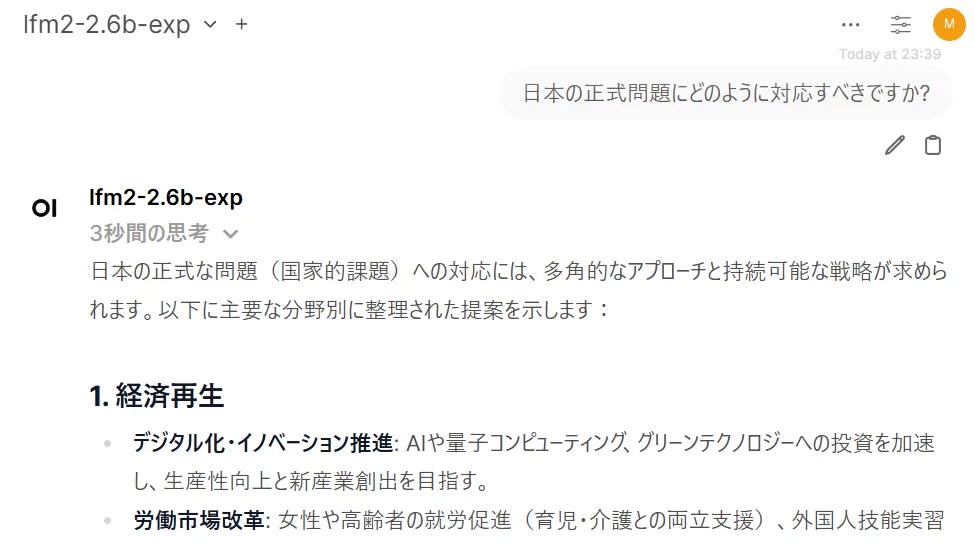
Faster Whisper API の認識結果
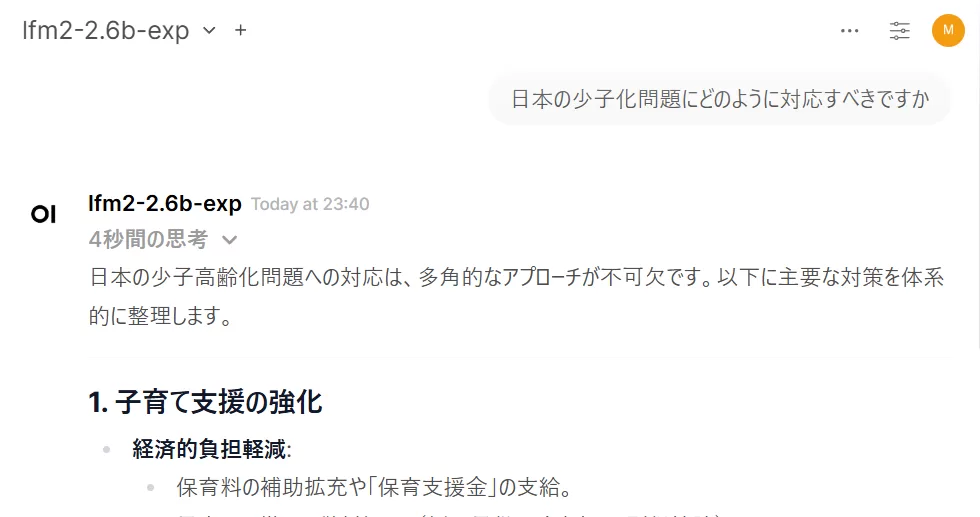
音声モード(リアルタイム会話)を試した結果
Open WebUIの音声モードも試した。
- 英語:成立する。Janglishでも会話可能
- 日本語:ほぼ成立しない
これは実装の問題というより、
日本語という言語構造とリアルタイムSTTの相性の問題だろう。
少なくとも現時点では、
日本語は「一発入力→確定→LLM送信」方式が現実解だ。
おまけ:LFM2は意外と一般知識を持っている
lfm2-2.6b-exp は軽量モデルだが、
日常会話や一般的な質問には意外と普通に答える。
lfm2-2.6b-exp
夏目漱石の代表作として、以下の3つの小説が挙げられます:
- 「吾輩は猫である」
自らを猫のように振る舞いながら、近代日本人の矛盾や社会風俗をユーモアに包んで描いた自伝的な随筆。- 「こころ」
人間関係や孤独、精神の深層を扱った長編小説で、主人公の苦悩とその背景にある歴史的・思想的な問題が描かれる。- 「三四郎」
若者の成長や社会への戸惑いをユーモアとアイロニーで描いた作品で、明治時代末期の日本社会を反映している。これらの作品は、日本文学の金字塔とも言われ、広く読まれています!
何より、スピードがバカっ速い。
この応答速度が音声対話のテンポを崩さない。
シビアな内容を議論したければ、テンポは落ちるが、gpt-oss にモデルを差し替えればいい。
音声入力と組み合わせると、「考えながら話す相手」として成立する。
モデルサイズより、入力品質の方が支配的だと改めて感じた。
結論
Open WebUIとLM Studioをそのまま組み合わせても、
日本語音声入力には多大な忍耐が要求される。
だが、
- Faster Whisper を使い
- WebAPI化し
- 環境変数で正しく刺す
この一手で、状況は一気に実用レベルへ跳ね上がる。
入力からテキスト化は、まさに一瞬だ!
ローカルLLMを音声前提で使いたいなら、
ここがスタートラインだ。
付録:Faster Whisper をWebAPI化して Open WebUI のSTTに接続する
この付録は「日本語音声入力を実用にする」ための最短手順。
LLM側(LM Studio / LocalAI)とは独立して動くので、まずSTTだけを成立させる。
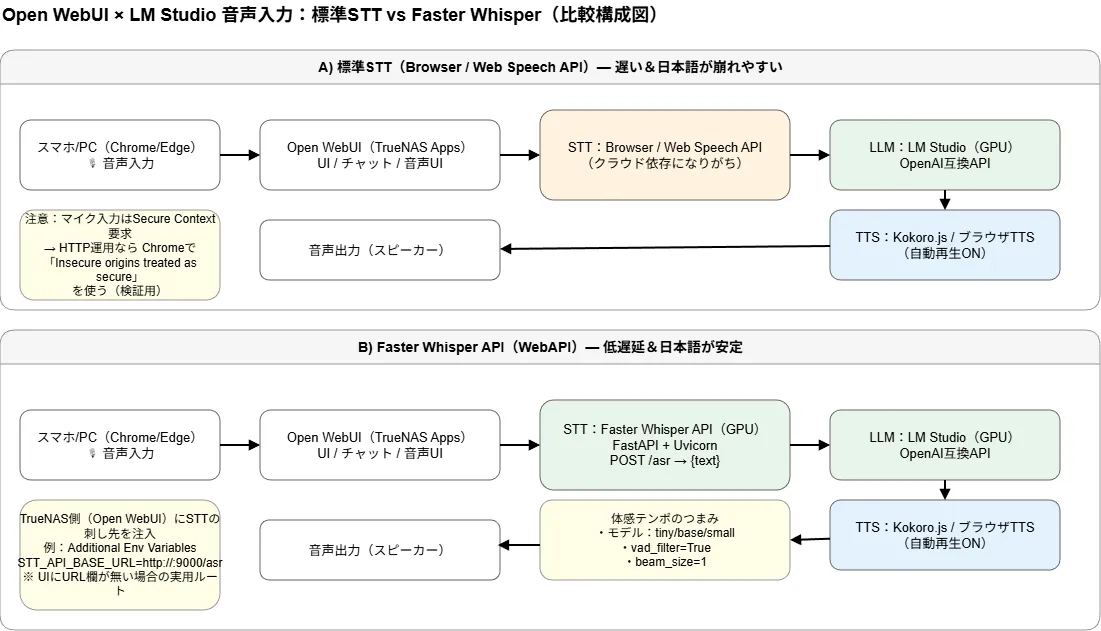
A. メインPC(GPU)に ASR API サーバを立てる
1) Python環境を作る
python -m venv .venvWindows:
.venv\Scripts\Activate.ps1依存を入れる:
pip install -U pip
pip install faster-whisper fastapi uvicorn[standard] python-multipart2) asr_server.py を作る
from fastapi import FastAPI, UploadFile, File
from faster_whisper import WhisperModel
import tempfile, os
app = FastAPI()
# GPUで回す。VRAM節約なら "small" や "medium" から。
model = WhisperModel("small", device="cuda", compute_type="float16")
@app.post("/asr")
async def asr(file: UploadFile = File(...), language: str = "ja"):
suffix = os.path.splitext(file.filename)[1] or ".wav"
with tempfile.NamedTemporaryFile(delete=False, suffix=suffix) as tmp:
tmp.write(await file.read())
tmp_path = tmp.name
try:
segments, info = model.transcribe(
tmp_path,
language=language,
vad_filter=True, # 無音区間を切る(体感テンポに効く)
beam_size=1, # 速度優先
temperature=0.0,
)
text = "".join(seg.text for seg in segments).strip()
return {"text": text, "language": info.language, "duration": info.duration}
finally:
os.remove(tmp_path)3) 起動
uvicorn asr_server:app --host 0.0.0.0 --port 9000LANから見えるか確認(ブラウザでもOK):
http://<メインPCのIP>:9000/openapi.json
※ ここが見えない場合は、まず Windowsファイアウォールで 9000/TCP を許可する。
B. Open WebUI(TrueNAS Apps)側の接続
あなたの環境(TrueNAS Apps)では、URLはUIではなく環境変数で指定するのが確実だった。
1) TrueNAS Apps → Open WebUI → Edit(設定)
Additional Environment Variables に追加:
- Name:
STT_API_BASE_URL - Value:
http://<メインPCのIP>:9000/asr
保存後、Open WebUI を再起動(環境変数は起動時に読まれる)。
2) Open WebUI の設定
- STT(音声テキスト変換エンジン):WebAPI
- 応答の自動再生:オン ※会話らしくしたいなら
(※ UIにURL入力欄が無いのは正常。刺し先は上の環境変数で指定する)

C. 体感テンポを上げる「3つのつまみ」
会話用途は、精度より「待ちの少なさ」が勝つ。
1) モデルサイズ
tiny / base / smallが会話向きlargeは精度は出るがテンポが落ちやすい
2) VAD(無音検出)
vad_filter=Trueは必須級- 話し終わりの“待ち”が目に見えて減る
3) beam_size
beam_size=1が速度最優先- beamを上げると精度は上がるが遅くなる
D. 成功時のサイン
- マイク入力後、ほぼ待たずにテキストが出る
- 日本語の助詞や係り受けが崩れにくい
- LFM2側の返答が“会話のテンポ”に乗る